





















Yapay zeka kişisel asistanlarının etkisi çok büyük, çeşitli alanlara yayılıyor ve sağlam bir iz bırakıyor....
Yazı Özetini Göster


Aslında, modelin iç kısmında, erken katmanlar zaten doğru cevabı gösteriyordu, sadece son katmanda kayboluyordu.
AI Halüsinasyonunun Gerçeği: Sonunda Unutmak

SLED’in Sırrı: Tek Bir Ses Değil, Birden Çok Ses

Güçlü Kanıt: SLED, DoLa’yı Kolayca Geçer

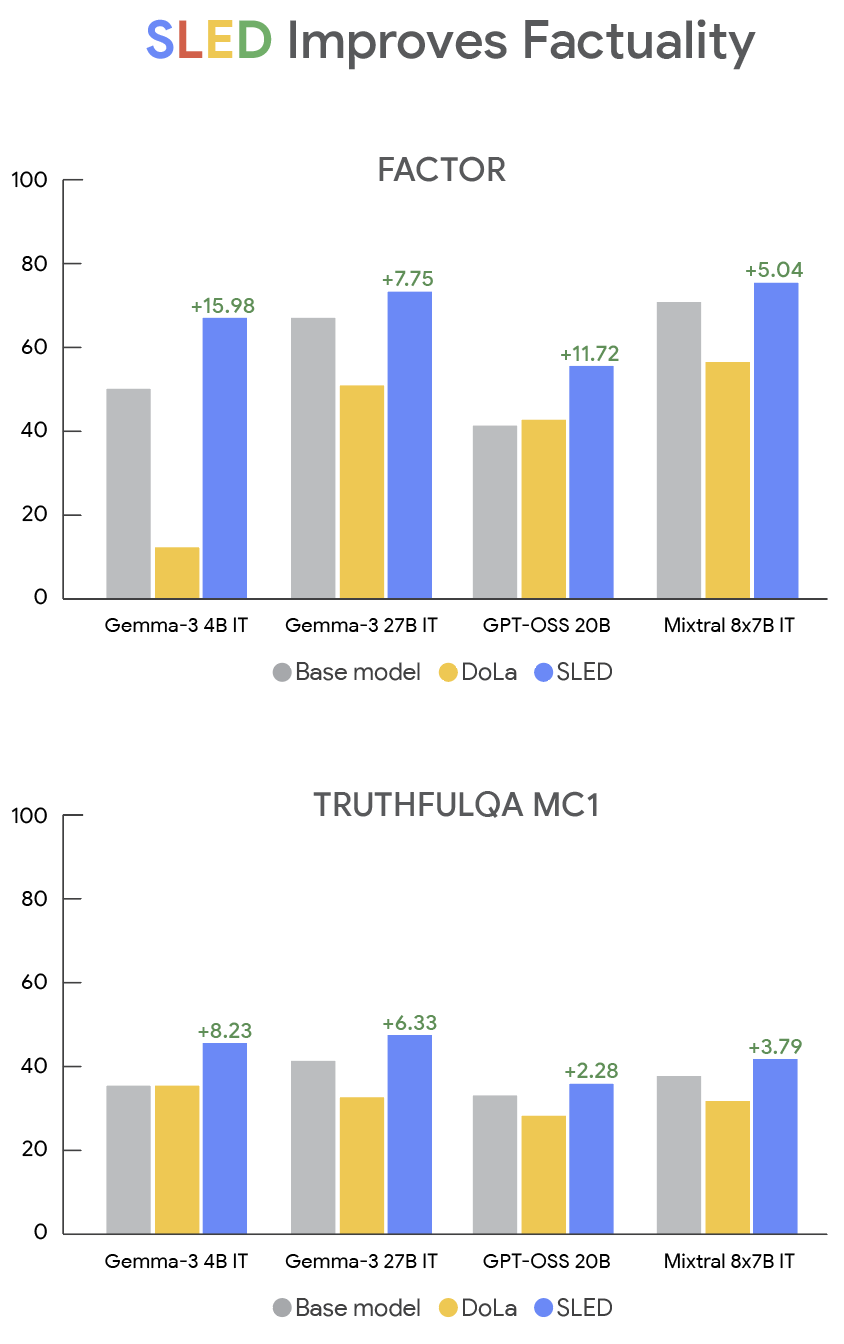

Güçlü Stand: SLED, Daha Büyük Modellerden Daha Akıllı


Kaynaklar:
https://research.google/blog/making-llms-more-accurate-by-using-all-of-their-layers/
https://arxiv.org/html/2411.02433v3?utm_source
https://github.com/JayZhang42/SLED
Yeni Zeka Haber Raporu
Büyük modellerin en can sıkıcı sorunu, ciddiyetle ‘saçmalama’ yapmasıdır. Eskiden sadece arama ve ek eğitimle düzeltilirdi. Ancak NeurIPS 2024’te Google’un yeni yöntemi SLED, bize şunu söylüyor: Model aslında biliyor, sadece son adımda unutuyor. Eğer her katmanın ‘sesini’ dikkate alırsak, hayallerden gerçeklere geri dönebilir.
On yıl boyunca, büyük modeller sürekli kapasite sınırlarını zorladı — makale yazmak, kod yazmak, şiir söylemek artık kolay.
Ama sorun şu ki, çoğu zaman ciddiyetle ‘saçmalıyorlar’: Vancouver’ı Britanya Kolumbiyası’nın başkenti yaptı, şömineye girip anında taşınıyor…
Bu ‘halüsinasyon’ hemen hemen yapay zekanın temel suçlarından biri haline geldi.
Birçok kişi bunun, modelin hiç bilmemesiyle ilgili olduğunu düşünüyor. Ancak Google Research’in NeurIPS 2024’te sunduğuSLED (Self Logits Evolution Decoding) ise, çarpıcı bir gerçeği ortaya koyuyor: Büyük modeller aslında cevapları biliyor, sadece son adımda unuttukları değil.
Makale adresi: https://arxiv.org/html/2411.02433v3?utm_source
Proje ana sayfası: https://github.com/JayZhang42/SLED
SLED’in enfes özelliği ise, tüm katmanların seslerini duyurmak ve birlikte sonucu belirlemektir.
Bu, büyük modellerin dışarıdan arama veya ek eğitim gerekmeden, hayalleri azaltabileceği anlamına gelir.
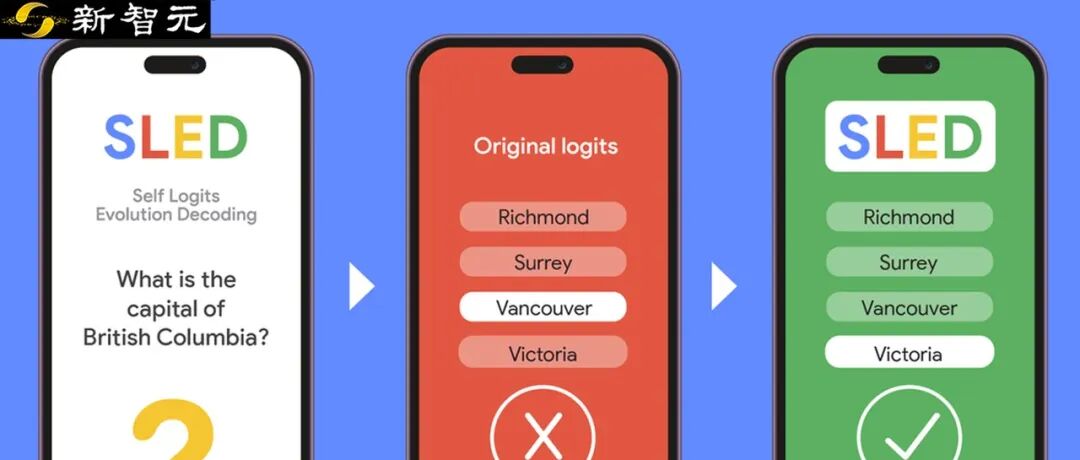
Gündelik yapay zeka kullanımlarımızda, sıkça tekrarlanan bir klişe vardır: ona “Britanya Kolumbiyası’nın başkenti hangi şehirdir?” diye sorarız, genellikle “Vancouver” der. Oysa gerçek cevap “Victoria”dır.
Bu kendinden emin ve yanlış cevap, sözde“AI” halüsinasyonu
SLED’in Çoktan Seçmeli Soruları Nasıl Daha İyi Cevapladığını Gösteren Bir Demostrasyon. Tüm katmanların bilgilerini kullanarak, SLED+LLM doğru cevabı (Victoria) bulur, değilse Britanya Kolumbiyası’nın daha iyi bilinen şehri Vancouver yerine.
Bu tür ‘AI halüsinasyonları’ çok yaygındır ve büyük modellerin güvenilirliği hakkında şüphe uyandırır.
Bu da, tıbbi, hukuk ve eğitim gibi kritik alanlarda ciddi sonuçlara yol açabilir: yanlış kararlar, yanıltıcı sonuçlar veya güvenin zedelenmesi.
Araştırmacılar uzun zamandır halüsinasyonun, büyük modellerin sistemik bir zorluğu olduğunu ve gerçekliği test etmek için TruthfulQA gibi ölçütler geliştirdiklerini söylüyorlar.
Geleneksel çözümler, genellikle dış kaynak arama (RAG), veya modele veri sorgulama, bilgi tabanı kullanma ve ince ayar yapma gibi yollar içerir.
Bu yaklaşımlar etkili olsa da, maliyetlidir ve sistem karmaşıktır: arama bazen yavaş olur, sonuçlar doğru olmayabilir, bilgi tabanı bakım ister ve ince ayar ise anotasyon ve kaynak gerektirir.
Son zamanlarda, Google araştırma ekibi NeurIPS 2024’te yeni bir yöntem olan SLED (Self Logits Evolution Decoding) tanıttı: amacı, dış bilgiye ihtiyacı olmadan, ek ince ayar yapmadan kendi içsel bilgisini kullanmak ve hayalleri azaltmak.
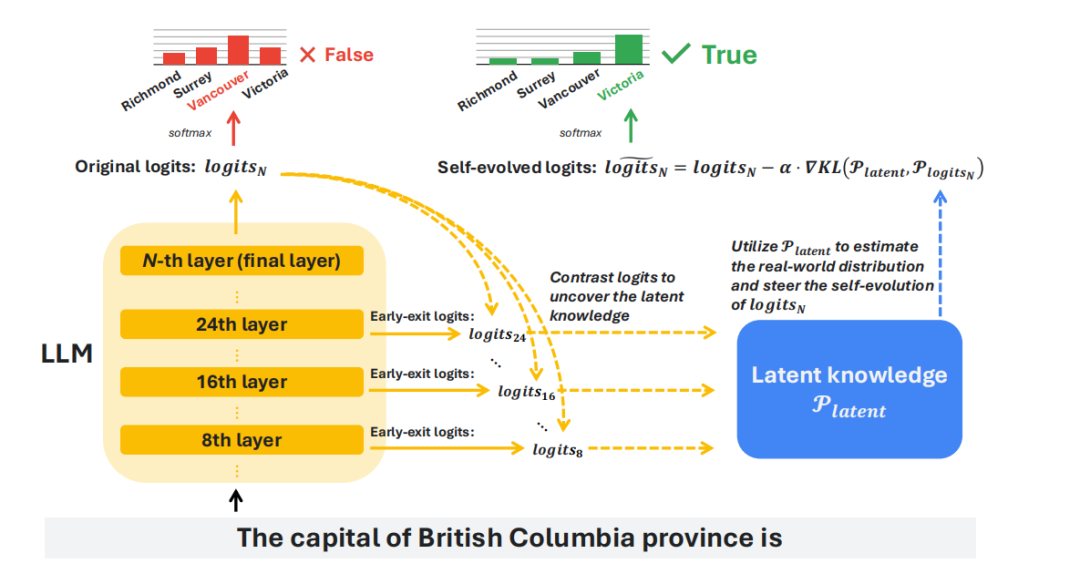
Sebep, modelin cevap üretirken her katmanda bir sonraki kelimenin tahminini (logits) yapmasıdır.
Ancak geleneksel yöntemler yalnızca son katmana bakar, bu da modelin en sık görülen kalıplara takılıp, gerçeklikle daha yakın olan orta katmandaki sinyalleri göz ardı etmesine neden olur.
SLED’in en önemli noktası ise, tüm katmanların tahminlerini dikkate almak ve bunları ağırlıklı olarak birleştirmektir.
Böylece, son katmanın “kütle” cevabına meyilli olduğu durumda, diğer katmanlardan gelen ek bilgiler, modelin gerçeklere daha uygun hale gelmesine katkı sağlar.
Geleneksel büyük modeller, çözümleme yaparken genellikle sadece son katmanın tahminine dayanır.
Ancak araştırmacılar, bu adımın fazla ‘keskin’ olabileceğini keşfettiler: son katman, eğitim verilerindeki en yaygın cevaplara yönelirken, orta katmanların zaten daha doğru bilgiler içerdiğini gözardı ediyor.
Araştırma ekibi SLED’i şu şekilde tanımlıyor:
SLED’in çerçevesi, erken katmanlar ile son katmandaki logitsleri karşılaştırarak, modellerin gizli bilgi hazinesini ortaya çıkarır ve bu potansiyel bilgilerin kendi kendini düzeltmesine yol açan yaklaşık gradyan yöntemiyle, gerçeklik ile uyumlu sonuçlar üretir.
Hayal üretmenin kökeni, modelin “bildikleri” ile “söyledikleri” arasındaki farktan kaynaklanır.
Model, eğitim sırasında gerçeğe uygun bilgileri gizlice öğrenmiş olabilir, ancak çıkarım yaparken ürettiği dağılım hâlâ sapmaya açıktır, bu da halüsinasyonların kaynağıdır.
SLED’in amacı ise, çözüm anında bu farkı gidermektir.
Bunun yolu ise, orta katman tahminlerini tek bir kelime listesine dönüştürüp, en sonunda en katmanın tahminiyle ağırlıklı olarak karıştırmaktır.
Bu sayede, ‘katmanlar arasındaki farklar’ kullanılarak, modelin yalnızca tek bir ses değil, birden çok ses duyulabilir hale gelir.
SLED çalışma akışı. Erken ve son katmandaki logitsleri karşılaştırmak, gizli dağılımı elde etmek ve buna dayanarak çıktıdaki hataları düzeltmek, sonuçları daha gerçekçi hale getirir.
Basit bir aritmetik problemiyle örnekleyelim:
Ash 6 tane oyuncak aldı, her biri 10 para. 4’ten fazla alırsa %10 indirim yapılıyor. Toplam ne kadar ödemeli?
Normal modeller genellikle “6×10=60” diye yanıt verir.
Ancak SLED, orta katmanda pek çok tahminin “×0.9” eklenmesine eğilim gösterdiğini fark eder ve doğru cevap olan 54’ü çıkartır.
SLED, orta katmandaki ipuçlarını kullanarak çıkışı düzeltiyor, böylece model yanlışlardan kaçınıp daha doğru sonuçlar alıyor.
Daha karmaşık matematik problemlerine bakalım:
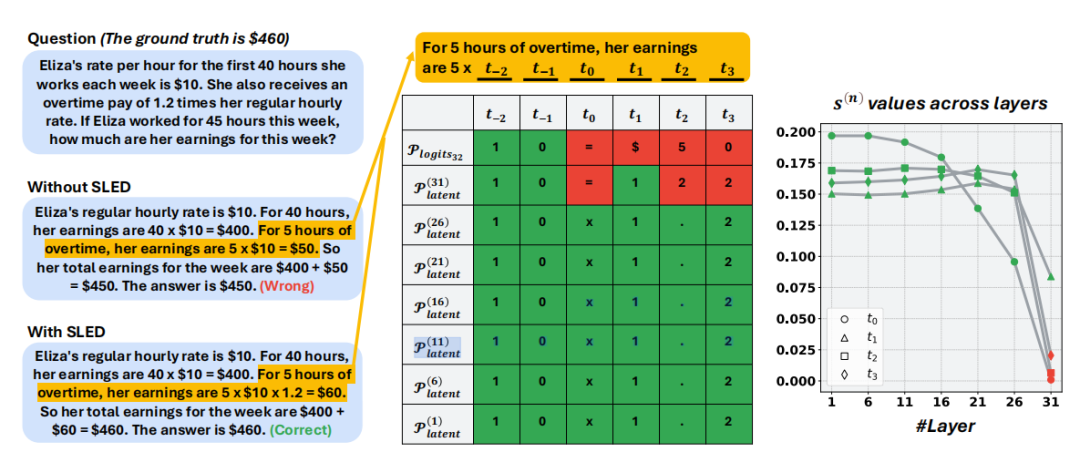
Eliza saatte 10 dolar kazanıyor, haftada ilk 40 saat normal ücret alıyor, fazlası ise 1.2 katı hesaplanıyor. O, 45 saat çalıştı, haftalık maaşı ne kadar olur?
Normal model genellikle “450 dolar” der, ancak 1.2 katı mesai ücretini unutur. SLED ise orta katmandan gelen sinyallerle sonucu düzelterek doğrusu olan 460 dolar olarak gösterir.
GSM8K maaş hesaplama örneği. Normal model yanlış olarak 450 dolar gösterirken, SLED orta katman sinyaliyle sonucu doğru olarak 460 dolar yapar.
Bu yöntem sayesinde, SLED herhangi bir yapı değiştirmeden veya ek eğitim yapmadan, bu kaybolmuş bilgileri çözüm aşamasında kullanabilir.
Bu araştırma Google Research ekibinden geldi.
Birincil yazar Jianyi Zhang, eğitim görürken bile önde gelen makalelerde ana yazar olarak yer aldı.
Takımda tecrübeli uzmanlar da var: araştırma bilimcisi Cyrus Rashtchian, araştırma yöneticisi Da-Cheng Juan ve makine öğrenmesi ile sistem optimizasyonu konusunda uzman birçok isim (Chun-Sung Ferng, Heinrich Jiang, Yiran Chen).
Bu başarıları NeurIPS 2024’e taşıdılar ve kodları GitHub’da açık hale getirdiler, daha çok kişinin kullanımına sunmayı hedefliyorlar.
Bu yöntemin kuramsal olarak karmaşık gelebileceğini düşünüyorsanız, deney sonuçları oldukça somut:
Araştırma ekibi, Gemma-3, Qwen-3, Mixtral ve GPT-OSS gibi açık kaynaklı modeller üzerinde kapsamlı testler yaptı.
Hem 1B’lik küçük modelleri hem de 20B, 27B gibi büyük modelleri kapsıyor.
Sonuçlar gösteriyor ki: SLED, model boyutu veya türü fark etmeksizin, hayalleri önemli ölçüde azaltıyor.
Gemma-3 serisinde özellikle etkili oldu:
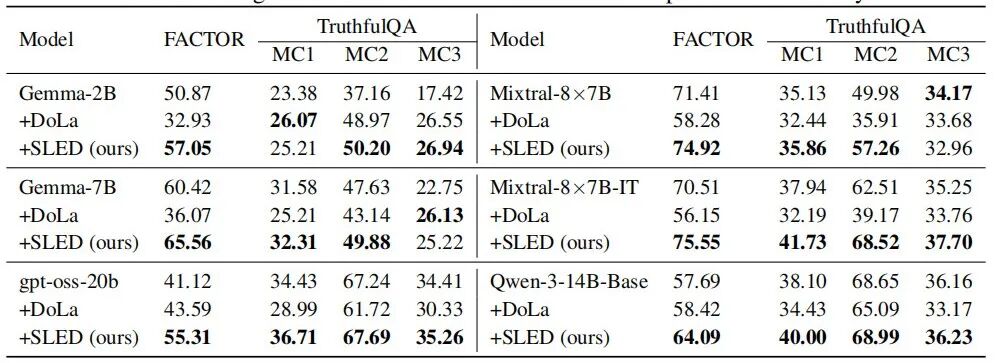
1B-PT modeli, FACTOR veri setinde %47.83 olan doğruluk oranını, SLED kullanımıyla %63.29’a çıkardı;
Gemma-3 27B-IT modeli ise, TruthfulQA MC1’de %41.14’den %47.47’ye yükseldi ve o zamanın en iyi yöntemi olan DoLa’dan tam 10 puan daha iyi oldu.
En küçük 1B’den en büyük 27B’ye kadar, SLED her zaman avantaj sağladı.
Gemma-3 serisi farklı modeller boyutlarında, FACTOR ve TruthfulQA’daki performansları. SLED, tüm modellerde ve eğitim türlerinde, temel yöntemleri ve DoLa’yı geçiyor.
Ayrıca, farklı modeller ailesiyle yapılan testler de SLED’in sağlamlığını kanıtlıyor.
GPT-OSS 20B’de FACTOR skoru %41.12’den %55.31’e çıktı; Mixtral-8×7B-IT’te %70.51’den %75.55’e yükseldi; Qwen-3-14B gibi modellerde ise TruthfulQA MC1’de %38.10’dan %40.00’a stabil yükselişler sağladı.
Karşılaştırıldığında, DoLa bu modellerde istikrarsız performanslar gösterirken, bazen hatta temel yöntemden daha kötü olabiliyor. SLED ise neredeyse tüm alanlarda öncülük ediyor.
SLED, GPT-OSS, Mixtral, Qwen gibi farklı modeller ailesinde, temel kavramlardan ve performanstan üstünlüğünü gösteriyor.
Çalışma hızı biraz daha yavaş olabilir, ancak deneme verileri, gecikmenin yaklaşık %4 seviyesinde olduğunu gösteriyor; bu da fark edilmiyor ve doğruluk oranını %16’ya kadar artırıyor.
Böylece, SLED sadece performans iyileştirme teknikleri değil, aynı zamanda uygulamaya konabilir ve kullanıcı deneyimini gerçekten değiştirecek bir çözüm stratejisidir.
SLED’in sağladığı değer, sadece birkaç cevabı düzeltmek değil, büyük modellere yeni bir bakış açısı kazandırmaktır:
Bilgi, sadece son katmanda değil, tüm ağ boyunca dağınık halde bulunuyor.
Geçmişte sadece nihai çıktıdan faydalanıyorduk, bu da sadece bir kişinin görüşünü dinlemek gibiydi ve diğer katmanlardaki daha gerçek sinyaller göz ardı ediliyordu.
SLED’in özellikle öne çıkan özelliği, yapıyı değiştirmeden, dış bilgiye ihtiyaç duymadan, bu gizli bilgileri ortaya çıkarmasıdır ve cevapların güvenilirliğini artırır.
Bu, özellikle şu anda çok önemli hale geldi: Arama ve öneri alanları, artık yapay zekayla yeniden şekilleniyor — Google’ın AI Overview özelliği, arama sonuçlarında yapay zeka tarafından oluşturulan özetleri doğrudan gösteriyor.
Araştırmalar gösteriyor ki, kullanıcılar yapay zekanın özetlerini gördüklerinde, genellikle alttaki geleneksel arama bağlantılarına daha az tıklıyor, bu da haber sitelerinin trafiğini büyük ölçüde azaltıyor.
Aynı zamanda, Google Discover akışında yapay zeka tarafından oluşturulmamış, doğruluğu belirlenmemiş ve hatta sahte haber içerikleri de öneriliyor.
İnsanlar giderek daha fazla yapay zekaya doğrudan cevap verdirirken, güvenilirlik kritik hale geliyor.
Çıkışlar sık sık yanlış olursa, güven kaybı katlanarak artar.
Bu bağlamda, SLED yalnızca birkaç yüzde puanlık doğruluk artışını sağlamakla kalmaz; aynı zamanda üretken yapay zekanın sınırlarını koruyarak, güvene dayalı bir gelecek inşa eder.
İleriye baktığımızda ise, SLED daha da ileri gidebilir:
SLED, denetimli ince ayar ve gözetimli öğrenme ile üretildiğinde, belli alanlara daha iyi uyum sağlayabilir;
Ayrıca, arama ve veri çekme yöntemleriyle entegre edilerek içerik ile bilgi kaynağı daha da güçlendirilebilir;
Gelecekte ise, görsel cevaplardan kod üretmeye, uzun içerik yazımına kadar pek çok alanda kullanılabilir.
Parametreleri ve veri miktarını artırmak yerine, mevcut potansiyel bilgileri daha akıllıca kullanmayı öğrenmek daha faydalı olacaktır.
SLED, parçalanmış hafızayı yeniden bütünlemenin yolu olan yeni bir yaklaşımı temsil ediyor — bu, modelin daha güvenilir ve daha güvenilir olmasını sağlar.
Sonuç olarak, yapay zeka yalnızca bilmiyor değil, aynı zamanda unutuyor; SLED ise onu hatırlatmaya çalışıyor.
İçerikte yer alan resimlerin telif hakkı sorunları varsa, lütfen bizimle iletişime geçin ve kaldırılmasını sağlayın.
Benzer Yazılar

Meta AI Yeni Donem HazirligindaMeta AI, yeni yapay zeka modelleri ve özellikleri için hazirliklarini sürdürüyor....
OpenAI GPT.com Alan Adini Satin Aldi mi?OpenAI, marka stratejisi olarak GPT.com alan adini satin almish...