





















Elon Musk’tan çılgın proje olarak duyurulan Grokipedia, teknoloji ve insanlığın bilgi arşivini uzaya taşıma...
Yazı Özetini Göster



01
02

03
04
05
06
VLM’deki veri eksikliği, modelin yeteneklerinin gelişimini etkilemiştir. Yakın zamanda yapılan bir araştırma, yetenekleri geliştirmek için AlphaGo’nun kendi kendini yineleme yöntemini öğrenmeye çalıştı.
AlphaGo, insanların satranç rekorlarını öğrenmeye dayanmıyor. “Sol ve sağ dövüş” yoluyla satranç oynamak için iki benliğe ayrılır, zaferin ve yenilginin sonuçlarından öğrenir ve kendi kendini yineleme optimizasyonuna ulaşır.
VLM, AlphaGo gibi, insan etiketli verilere dayanmadan kendi kendine oyun yoluyla kendisini “eğitebilir” mi?
Duke Üniversitesi, Singapur Ulusal Üniversitesi, Maryland Üniversitesi ve Adobe’den araştırmacılar tarafından önerilen “Vision-Zero” çalışması, VLM’nin sıfır denetimli eğitimi için genel bir çerçeve sağlıyor.
Basitçe söylemek gerekirse araştırmacılar, “Gizli kimdir” oyununa benzer şekilde yapay zekanın kendi kendine oyun oynayarak öğrenmesine olanak tanıyan bir çerçeve tasarladılar. VLM, oyun kurallarını ve “alternatif eğitim” stratejilerini formüle ederek kendi gelişimini sağlayabilir.
Deneysel sonuçlar, Vision-Zero’nun eğitim için herhangi bir etiketli veri kullanmadan, akıl yürütme, grafik soru yanıtlama ve Vizyon Merkezli anlama görevlerinde diğer etiketli SOTA eğitim sonrası yöntemlerini geride bıraktığını göstermektedir.
Aşağıda bu araştırma çalışmasının ayrıntıları yer almaktadır.
Şu anda kod, model ve proje ana sayfası yayınlandı:
Proje ana sayfası ve kodu:https://github.com/wangqinsi1/Vision-Zero
Kağıt bağlantısı:https://arxiv.org/abs/2509.25541
Bu makalenin yazarları arasında Wang Qinsi, Lin Yueqian, Profesör Li Hai, Duke Üniversitesi’nden Profesör Chen Yiran, Singapur Ulusal Üniversitesi’nden Liu Bo, Maryland Üniversitesi’nden Profesör Zhou Tianyi ve Adobe araştırmacıları Shi Jing, Wan Kun ve Zhao Wentian yer alıyor.
Arka plan tanıtımı
Her ne kadar VLM şu anda çok modlu görevlerde iyi performans gösterse de, eğitim aşırı derecede manuel olarak açıklanan verilere ve dikkatle tasarlanmış takviyeli öğrenme ödüllerine dayanıyor. Bu bağımlılık getiriyorVeri kıtlığı sorunu: Çok modlu açıklama pahalıdır, bu da eğitim verilerinin ölçeğini ve çeşitliliğini sınırlar. aynı anda var olmakbilgi tavanı: Model yetenekleri insan denetimi sınırlarıyla sınırlıdır ve mevcut insan bilgi ve stratejilerini aşmak zordur. AlphaGo tarafından kullanılan kendi kendine oyun teknolojisi, modeli kendi kopyalarıyla rekabet etmek ve etkileşimde bulunmak ve otomatik olarak geri bildirim almak için kullanır, manuel denetime bağımlılığı ortadan kaldırırken hesaplamaları verilere dönüştürür. Bu, model ilerlemesini desteklemeye devam etmesine ve insan yeteneklerinin üst sınırını aşmasına olanak tanır. Ancak VLM’nin çok modlu özellikleri nedeniyle, kendi kendine oyunun VLM’de uygulanmasına ilişkin şu anda az sayıda sistematik çalışma bulunmaktadır. Bu amaçla araştırma ekibi, VLM’nin özelliklerine uyum sağlayan bir dizi kendi kendine oyun çerçevesi Vision-Zero tasarladı. Bu çerçeve aşağıdaki özelliklere sahiptir:
(1) Stratejik kendi kendine oyun çerçevesi: Vision-Zero, VLM’yi şablon olarak sosyal akıl yürütme oyunlarına dayalı bir ortamda eğitir ve aracının, kendi kendine oyun süreci sırasında manuel açıklama olmadan otomatik olarak yüksek karmaşıklık akıl yürütme verileri oluşturmasına olanak tanır.
(2) Herhangi bir resim biçimi girdi olarak kullanılabilir: Kısıtlamalara sahip önceki oyunlaştırılmış eğitim çerçevelerinden farklı olarak Vision-Zero, oyunları herhangi bir resim biçiminde başlatabilir; bu, modelin birçok farklı alandaki yeteneklerde karşılık gelen iyileştirmeler elde etmesine olanak tanır ve iyi bir genelleme performansına sahiptir.
(3) Sürekli performans iyileştirmesi: Araştırma ekibi, kendi kendine oyun ve takviyeli öğrenmeyi doğrulanabilir ödüllerle (RLVR) dönüşümlü olarak optimize eden bir kendi kendine oyun stratejisi optimizasyon algoritması (Yinelemeli-SPO) önerdi. Bu algoritma, geleneksel kendi kendine oyun algoritmalarındaki yaygın performans darboğazı sorununu çözer.
Eğitim için herhangi bir etiketli veri kullanmamasına rağmen Vision-Zero, akıl yürütme, grafik soru yanıtlama ve Vizyon Merkezli anlama görevleri gibi birden fazla alanda diğer etiketli SOTA eğitim sonrası yöntemlerinden daha iyi performans gösterir.
Satranç tahtasından gerçeğe:
AlphaGo’nun kendi kendine oyun düşüncesinin genelleştirilmesi
OpenAI’nin ilk önemli teknik rotalarından biri olan kendi kendine oyun, aynı zamanda yapay zekanın gelişimindeki birçok dönüm noktası olayı için de önemli bir itici güçtür. Tipik örnekler arasında AlphaGo’nun 2016’da Lee Sedol’e karşı kazandığı zafer ve OpenAI Five’ın 2019’da Dota 2’de dünya şampiyonu OG takımını mağlup etmesi yer alıyor. İnsanlar kişisel oyunun belirli alanlarda insan zekasını büyük ölçüde aştığını gördüklerinde, genellikle bu fikri daha açık senaryolara uygulamanın mümkün olup olmadığını da düşünüyorlar. Ancak AlphaGo’nun satranç tahtasından gerçekliğe geçebilmesi için aşağıdaki sorunların çözülmesi gerekiyor:
(1) Temsilcinin oyunu kazanmak için öğrendiği beceriler, hedef görev için gereken becerilerle oldukça tutarlı olmalıdır.
(2) Oyun ortamı, çok çeşitli hedef görevlerin koşul (1)’i karşılayabilmesini sağlayacak kadar çeşitli ve karmaşık olmalıdır.
(3) Beceri gelişimi ölçeklenebilir olmalıdır: Kendi kendine oyun ilerledikçe, eğitimin sabit bir üst sınıra yakınlaşmasına izin vermek yerine, daha güçlü etmenlerin ortaya çıkabilmesi için ortamın zorluğu artmaya devam etmelidir.
“Gizli Kimdir” gibi sosyal akıl yürütme oyunlarından ilham alan araştırma ekibi, yukarıdaki sorunları çözmek için eksiksiz bir kendi kendine oyun kuralları seti tasarladı. Özel kurallar aşağıdaki gibidir:
(1) Oyunda n sivil ve 1 gizli görev var. Oyuncular öncelikle rolleri hakkında bilgilendirilir.
(2) Her oyuncu bir resim alacaktır ve gizli resim sivillerinkinden biraz farklıdır (bir nesnenin eksik olması, eklenmesi veya değiştirilmesi gibi).
(3) İpuçları aşaması: Her oyuncu kendi resmini gözlemler ve resmin içeriğini açıklamak için sözlü bir ipucu verir (bu bir nesne açıklaması, çıkarım yapılan bilgi vb. olabilir).
(4) Karar verme aşaması: Birden fazla ipucu verildikten sonra karar verme aşamasına geçilir. Oyuncular, gizli ajanı bulmak için oy vermek üzere ipuçlarını kendi resimleriyle birlikte kullanırlar.
Bu oyun son derece stratejik ve zorludur. Gizli görevdeki ajanın, açığa çıkmamak için diğer insanların ipuçlarına dayanarak kendini çıkarması ve gizlemesi gerekiyor. Sivillerin yeterince doğru ancak sır sızdırmayan ipuçları vermesi ve aynı zamanda şüpheli noktaları bulmak için diğer insanların ipuçlarını analiz etmesi gerekiyor. Bu şekilde, Temsilci oyun sırasında yeterince uzun ve karmaşık bir akıl yürütme zinciri oluşturabilir ve rakibin yeteneği geliştikçe karşılaştığı zorluklar giderek büyüyecek ve daha güçlü görsel anlayış ve akıl yürütme yeteneklerine ilham verecektir.
Etki alanından bağımsız veri girişi
Bu oyunun başlaması için girdi olarak yalnızca iki biraz farklı görüntü çifti gerekir. ChatGPT veya nanobanana gibi mevcut güçlü görüntü düzenleme araçları sayesinde verilerin oluşturulması son derece basit ve düşük maliyetli olduğundan bu çerçevenin uygulama senaryoları çok geniştir. Araştırma ekibi, eğitim verileri olarak tamamen farklı üç sahne görüntüsü girdisi kullandı:
(1) CLEVR sentetik sahne: CLEVR oluşturucu kullanılarak 2000 çift görüntü otomatik olarak oluşturuldu. Orijinal görüntüde rastgele düzenlenmiş 4-6 nesne bulunur ve değiştirilmiş görüntüde rengi ve şekli değiştirilmiş iki nesne bulunur.
(2) Grafik verileri: ChartQA eğitim setinden orijinal görüntüler olarak rastgele 1.000 grafik seçildi ve ilgili değiştirilmiş görüntüleri oluşturmak için grafiklerdeki sayısal nitelikleri rastgele değiştirmek için Gemini2.5-Flash kullanıldı.
(3) Gerçek dünya görüntüleri: Yüksek kaliteli gerçek dünya tek turlu görüntü düzenleme çiftlerini içeren ImgEdit eğitim setinden 1000 görüntü çifti rastgele seçildi.
Kısmi dengeden sürdürülebilir iyileştirmeye
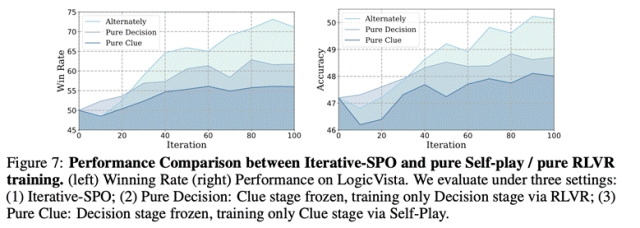
Saf kendi kendine oyun eğitimi, yerel dengeye düşme eğilimindedir ve yeni akıl yürütme yollarını keşfetmek zordur; bireysel takviyeli öğrenme yöntemleri de mevcut problem setinde uzmanlaştıktan sonra bilgi doygunluğuna eğilimlidir. Bu sorunları hafifletmek için yazar ekibi iki aşamalı alternatif eğitimin kullanılmasını önerdi: karar verme aşamasının performansı ipucu aşamasının doygun olduğunu gösterdiğinde, zorluğu artırmak için ipucu eğitimine yöneliyor ve bunun tersi de karar verme aşamasına geri dönüyor. Bu yönteme Yinelemeli Kendi Kendine Oynama Politikası Optimizasyonu adı verilir. Deneyler, iki aşamalı dönüşümlü eğitimin performansının, tek aşamalı eğitimden önemli ölçüde daha iyi olduğunu göstermektedir. Karşılaştırma aşağıdaki gibidir.
Deneysel sonuçlar
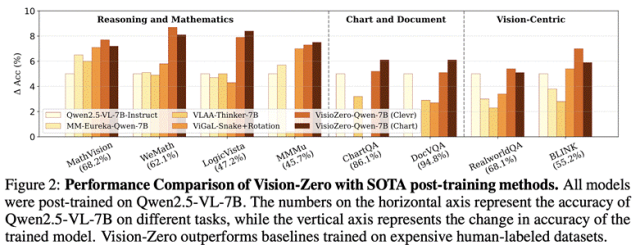
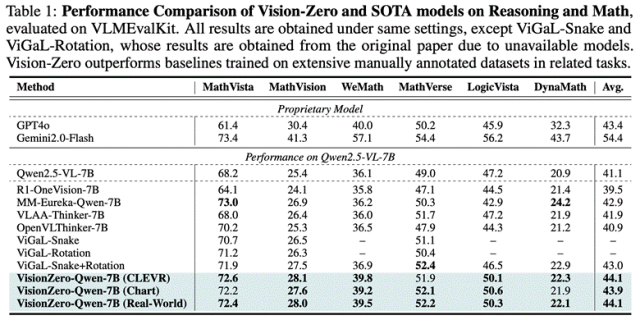
Güçlü görev genelleme yeteneği.Vision-Zero çerçevesi altında eğitilen VLM’nin daha geniş bir muhakeme ve matematik görev yelpazesine genelleştirilip genelleştirilemeyeceğini değerlendirmek amacıyla yazarın ekibi, modeli altı kıyaslama veri seti üzerinde test etti (sonuçlar için Tablo 1’e bakınız). Deneyler, eğitim için etiketlenmiş veriler kullanılmasa bile Vision-Zero’nun çeşitli kıyaslamalarda etiketleme gerektiren diğer SOTA yöntemlerine göre daha tutarlı olduğunu göstermektedir. Bunlar arasında, VisionZero-Qwen-7B (CLEVR, Real-World) temel değerle karşılaştırıldığında yaklaşık %3 oranında iyileşme gösterirken VisionZero-Qwen-7B (Chart) yaklaşık %2,8 oranında iyileşme gösterirken mevcut optimal temel yöntem yalnızca %1,9 civarındadır. Temel yöntemin eğitim için çok sayıda matematik ve muhakeme örneği gerektirdiğini, Vision-Zero ortamının ise açıkça matematik görevlerini içermediğini belirtmekte fayda var. Yalnızca doğal dil strateji oyunları yoluyla mantıksal akıl yürütmeyi geliştirir ve öğrenilen yetenekleri daha geniş bir yelpazedeki matematik ve akıl yürütme görevlerine etkili bir şekilde aktarır, hatta büyük ölçekli görev verileri üzerinde özel olarak eğitilmiş modelleri bile geride bırakır.
Yetenekler arası olumsuz aktarımın azaltılması
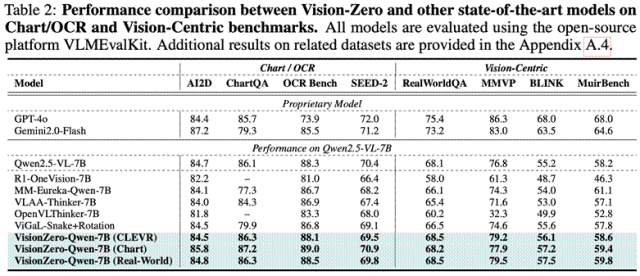
VLM eğitim sonrası en önemli zorluklardan biri çapraz yetenek negatif transferidir, yani belirli bir görev üzerinde eğitim sonrasında model diğer görevlerde daha da kötüleşir. Tablo 2, çıkarım ve matematik verileri üzerine eğitim sonrasında temel modelin performansının önemli ölçüde düştüğünü göstermektedir. Örneğin MM-Eureka-Qwen-7B, ChartQA’da yaklaşık %10 düşüyor. Buna karşılık, Vision-Zero tarafından eğitilen modeller olumsuz aktarımı etkili bir şekilde hafifletebilir: VisionZero-Qwen-7B (CLEVR), dört grafik/OCR görevinde yalnızca ortalama %0,2 oranında düşüş gösterirken, görme görevlerini önemli ölçüde iyileştirir; VisionZero-Qwen-7B (Chart) tüm grafik/OCR kıyaslamalarında iyileşme gösterir ve görsel görevlerde ortalama %1 oranında artış gösterir. Bu, Vision-Zero’nun çoklu yetenek stratejisi eğitiminin, geleneksel tek görevli eğitimdeki olumsuz transfer sorununu önemli ölçüde hafiflettiğini göstermektedir.
Aydınlanma
Vision-Zero, kendi kendine oynamanın tek bir görevden genel bir göreve kadar uygulanabilirliğini ve büyük potansiyelini kanıtlıyor. Açık ve ölçeklenebilir bir oyun ortamı oluşturarak, manuel açıklama bağımlılığından kurtulur, veri ve bilgi darboğazlarını aşar ve modelin, özel görev eğitimine ihtiyaç duymadan sürdürülebilir yetenek gelişimi ve alanlar arası genelleme elde etmesini sağlar. Aynı zamanda, iki aşamalı alternatif optimizasyon, kendi kendine oynamanın yaygın yerel denge problemlerini etkili bir şekilde ortadan kaldırır. Dahası, kendi kendine oyun yoluyla eğitilen VLM, tek bir görev üzerinde eğitimin geleneksel çapraz yetenek olumsuz transfer sorununu etkili bir şekilde hafifletir.
Orijinal makaleleri yeniden basmak için lütfen WeChat’i ekleyin: Founderparker
Benzer Yazılar

Meta Reality Labs, yüzey elektromiyografi (sEMG) tabanlı yeni nesil sinir ara yüz bilekliğini tanıttı. Dakikada...
Yapay zekâ teknolojilerinin küresel çapta hızla geliştiği bir dönemde, Çin merkezli yenilikçi şirketler de bu...
