





















Canlı yayındaki kazalar, internet kullanıcılarının eleştirileri, uzmanların kötümser yorumları… GPT-5'in tanıtım günü başlayan ilk...
Yazı Özetini Göster

Bilgisayarlı görü alanındaki çoğu alt akış görevi 2 boyutlu görüntü anlama (özellik çıkarma) ile başlar.
Özellik çıkarma, anlamsal anlama ve görüntü segmentasyonu gibi temel CV görevlerindeki en güçlü üç model, sırasıyla tam denetim, zayıf denetim ve öz denetim olmak üzere üç ana veri eğitim paradigmasını temsil eden SAM, CLIP ve DINO’dur.
Yapay zekâ alanında, yapay zekâ modellerinin insan gözetimi olmadan otonom bir şekilde öğrenmesini sağlayan öz-denetimli öğrenme (SSL), modern makine öğreniminde ana akım bir paradigma haline gelmiştir. SSL, büyük metin veritabanları üzerinde ön eğitim yoluyla genel temsil yetenekleri kazanan büyük dil modellerinin yükselişini tetiklemiştir.
Etiketli veriler gerektiren SAM modeli ve eğitim için görüntü-metin çiftlerine dayanan CLIP modeliyle karşılaştırıldığında, öz-denetimli öğrenmeye dayanan DINO, öğrenme sinyallerini doğrudan görüntüden üretme avantajına sahiptir. Daha düşük bir veri hazırlama eşiğine sahiptir, daha gelişmiş görüntü özellikleri elde etmek için daha büyük ölçekli veri öğrenimini daha kolay gerçekleştirir ve daha güçlü bir genelleme sunar.
Meta, 2021 yılında ViT üzerine inşa edilen ve etiketleme olmadan anlamsal segmentasyon ve nesne tespiti gibi görevlerde oldukça kullanışlı özellikleri öğrenebilen DINO’yu piyasaya sürdü ve bu sayede alt akış bilgisayarlı görme görevlerinde SAM modelinin boşluğunu doldurdu.
2023 yılında DINOv2 yayınlandı ve açık kaynaklı hale getirildi. DINO modelinin geliştirilmiş bir versiyonudur. Daha büyük ölçekli veriler kullanır, eğitim kararlılığını ve çok yönlülüğünü vurgular ve doğrusal sınıflandırma, derinlik tahmini ve görüntü alma gibi alt akış görevlerini destekler; performansı zayıf gözetimli yöntemlerin performansına yaklaşır veya onu aşar.
DINOv2, yalnızca Meta tarafından ImageBind gibi çok modlu modeller için görsel temsil temeli olarak kullanılmamakta, aynı zamanda çeşitli görmeyle ilgili araştırma çalışmalarında klasik bir model olarak da yaygın olarak kullanılmaktadır.
DINOv2 veri işleme hattı diyagramı
DINOv2 iki yıldır piyasada olmasına rağmen, eksiksiz ve ölçeklenebilir bir ViT yapısıyla CV alanındaki en gelişmiş görüntü modellerinden biridir. Ne yazık ki, eğitim verisi miktarı yeterince büyük değildir ve yüksek çözünürlüklü görüntülerin yoğun özelliklere sahip olduğu görevler için hala ideal değildir.
Bugün, DINOv2’nin bu iki eksikliği tamamen giderildi. Meta, daha yüksek kaliteli ve yüksek çözünürlüklü görsel özellikler üretmek için öz-denetimli öğrenmeyi de kullanan genel amaçlı, son teknoloji ürünü bir görsel temel modeli olan DINOv3’ü resmen başlattı ve açık kaynaklı hale getirdi.
DINOv3, tek bir dondurulmuş görüntü omurga ağının, nesne algılama ve anlamsal segmentasyon gibi uzun süredir devam eden yoğun tahmin görevlerinde en son teknoloji çözümlerinden daha iyi performans gösterdiğini ilk kez göstermektedir.
DINOv3’ün çığır açan performansının özü, yenilikçi özdenetimli öğrenme tekniklerinde yatmaktadır. Bu teknikler, etiketli verilere olan ihtiyacı tamamen ortadan kaldırarak eğitim için gereken zaman ve kaynakları önemli ölçüde azaltır. Bu sayede eğitim verileri 1,7 milyar görüntüye ve model parametre boyutu 7 milyara çıkarılmıştır . Bu etiketsiz yaklaşım, etiketlerin kıt, maliyetli veya hatta elde edilmesinin imkansız olduğu uygulamalar için uygundur.
Meta, MAXAR uydu görüntüleriyle eğitilmiş bir uydu görüntü omurgası da dahil olmak üzere, tüm DINOv3 omurga ağını ticari bir lisans altında açık kaynaklı hale getirdiğini duyurdu . Meta ayrıca, topluluğun sonuçlarını çoğaltmasını ve daha ileri araştırmalar için bunları temel almasını sağlamak amacıyla bazı alt görevler için değerlendirme başlıklarını da yayınladı. Geliştiricilerin hızla başlayıp DINOv3 tabanlı uygulamalar geliştirmeye başlamalarına yardımcı olmak için örnek not defterleri de mevcuttur.
Meta’nın yeni modeliyle ilgili olarak internet kullanıcıları, “Meta’nın bittiğini düşünüyordum ama sonunda yeni bir şeyle karşımıza çıktılar.” şeklinde espri yaptı.
Kendi kendine denetlenen öğrenme modellerinde yeni bir dönüm noktası
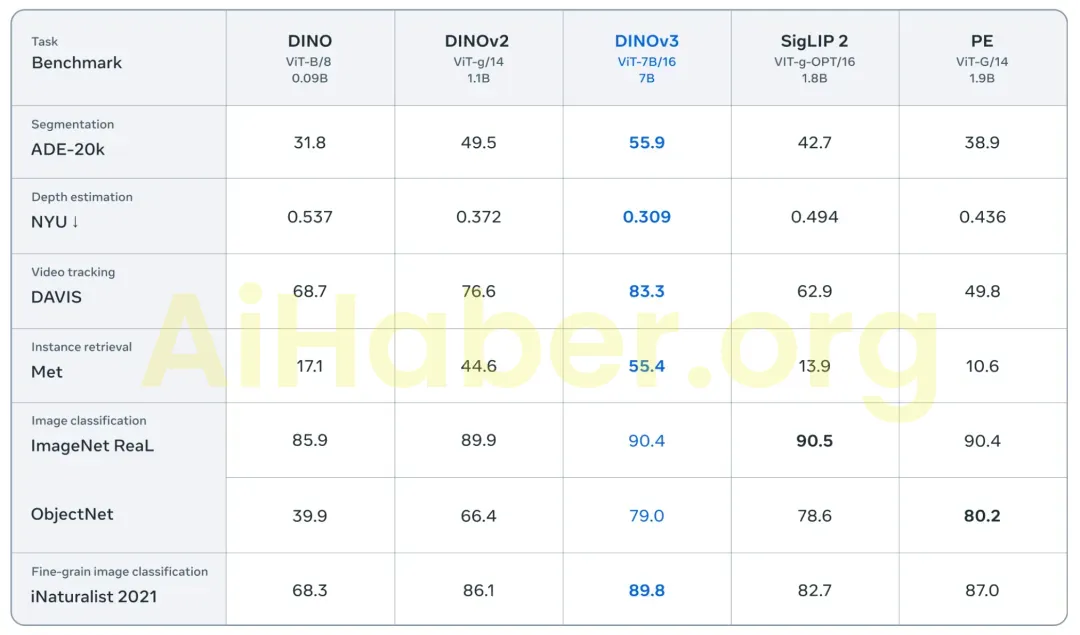
DINOv3 yeni bir dönüm noktasına ulaştı: İlk kez, öz-denetimli öğrenme (SSL) modellerinin çok çeşitli görevlerde zayıf denetimli modellerden daha iyi performans gösterebileceğini kanıtladı . Önceki nesil DINO modelleri, anlamsal segmentasyon ve tek gözlü derinlik tahmini gibi yoğun tahmin görevlerinde önemli ilerlemeler kaydetmişken, DINOv3 onları geride bıraktı.
DINOv3, SigLIP 2 ve Perception Encoder gibi son teknoloji güçlü modellerle karşılaştırılabilir veya daha iyi bir performansa ulaşırken, yoğun tahmin görevlerindeki performans farkını önemli ölçüde genişletiyor.
DINOv3, çığır açan DINO algoritması üzerine kuruludur, herhangi bir meta veri girişi gerektirmez ve önceki yöntemlerin eğitim hesaplamasının yalnızca bir kısmını gerektirirken, yine de mükemmel performansa sahip görsel bir temel modeli üretir.
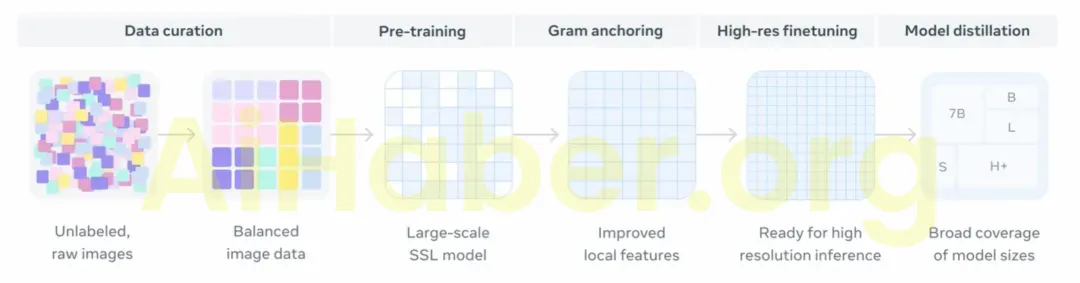
DINOv3, yoğun özelliklerin çökme sorununu etkili bir şekilde hafifleten ve DINOv2’den daha iyi ve daha temiz yüksek çözünürlüklü yoğun özellik haritalarına sahip olan yeni bir Gram Ankraj stratejisi de dahil olmak üzere bir dizi yeni iyileştirme sunar ; sabit konumlu kodlamanın sınırlamalarından kaçınan ve farklı çözünürlüklerdeki girdilere doğal olarak uyum sağlayabilen RoPE’nin döner konum kodlamasının tanıtımı.
Bu yeni geliştirmeler , “ağırlıkları dondurma ” gibi katı kısıtlamalar altında bile, birden fazla son derece rekabetçi alt akış görevinde (nesne tespiti gibi) mevcut en son teknoloji performansına ulaşmasını sağlar . Bu, araştırmacıların ve geliştiricilerin artık model üzerinde hedefli ince ayar yapmasına gerek kalmayacağı anlamına gelir ve bu da modelin kullanılabilirliğini ve uygulama verimliliğini daha geniş bir senaryo yelpazesinde büyük ölçüde artırır.
Yüksek çözünürlük, yoğun özellikler ve yüksek doğruluk
DINOv3’ün en önemli özelliklerinden biri, mevcut modellere kıyasla yüksek çözünürlüklü görüntülerde ve yoğun görüntü özelliklerinde kaydettiği ilerlemedir; bu da DINOv2 döneminin sorunlu noktalarını önemli ölçüde iyileştirir .

Örneğin, bu görsel 4096×4096 boyutlarında bir meyve tezgahının görseli. Burada belirli bir meyveyi bulmak, çıplak gözle bile olsa, biraz baş döndürücü…
Meta, DINOv3 çıkış özellikleri tarafından oluşturulan kosinüs benzerlik grafiğini görselleştirerek, kırmızı çarpı ile işaretlenmiş bir yama ile görüntüdeki diğer tüm yamalar arasındaki benzerlik ilişkisini gösterir.
Yakınlaştırıp doğru olup olmadığına bakın, değil mi?
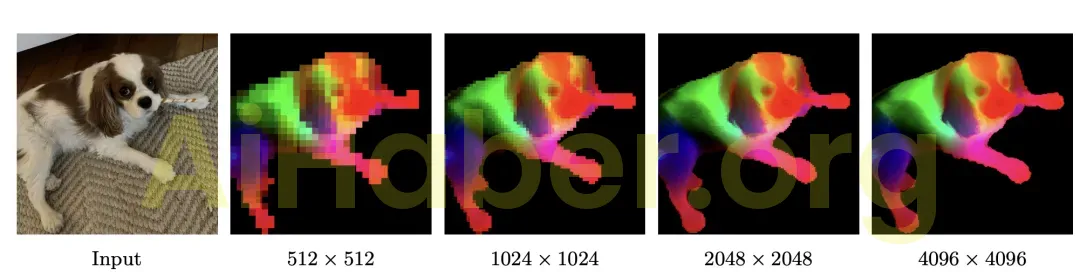
Yoğun özellikler söz konusu olduğunda Meta, DINOv3’ün yoğun özelliklerini, özellik uzayında temel bileşen analizi (PCA) gerçekleştirerek ve ilk üç temel bileşeni RGB renk kanallarına eşleyerek görselleştirir. PCA’yı konu alanına odaklamak için Meta, özellik haritasında arka plan çıkarma işlemi gerçekleştirir.
Görüntü çözünürlüğü arttıkça DINOv3 net, keskin ve anlamsal olarak tutarlı özellik haritaları üretebilmektedir .
Meta, öz-denetimli öğrenmenin nispeten geç ortaya çıktığını ancak hızla geliştiğini ve son yıllarda ImageNet’teki doğruluk tavanına ulaştığını söyledi.
Ölçeklenebilir, verimli ve herhangi bir ayarlama gerektirmez
DINOv3 , model boyutunda yedi kat, eğitim veri kümesinde ise 12 kat artışla selefi DINOv2 üzerine inşa edilmiştir . Modelin çok yönlülüğünü göstermek için Meta, 15 farklı görsel görev ve 60’tan fazla kıyaslama ölçütü üzerinden değerlendirilmiştir. DINOv3’ün görsel omurga modeli, tüm yoğun tahmin görevlerinde özellikle iyi performans göstererek, sahne düzeni ve fiziksel yapı konusunda derinlemesine bir anlayış sergilemiştir.

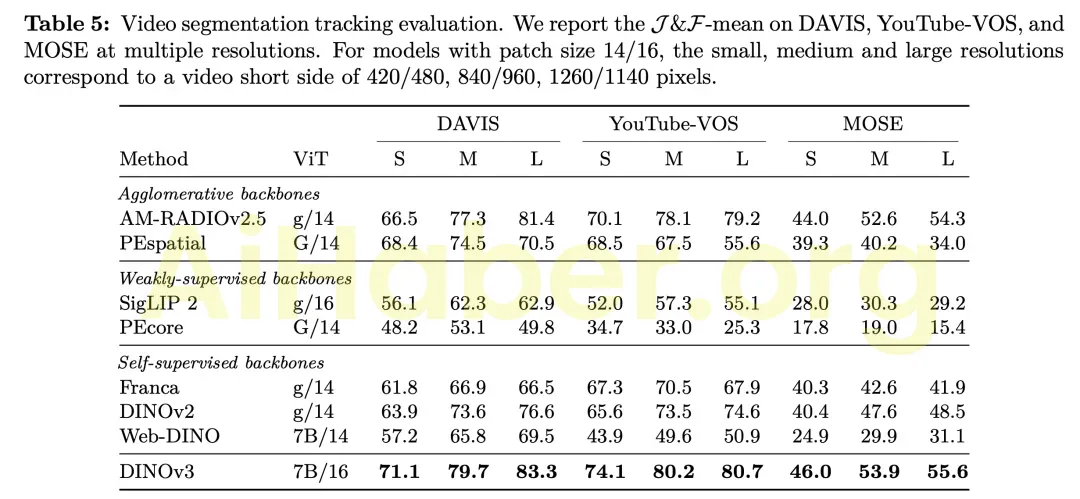
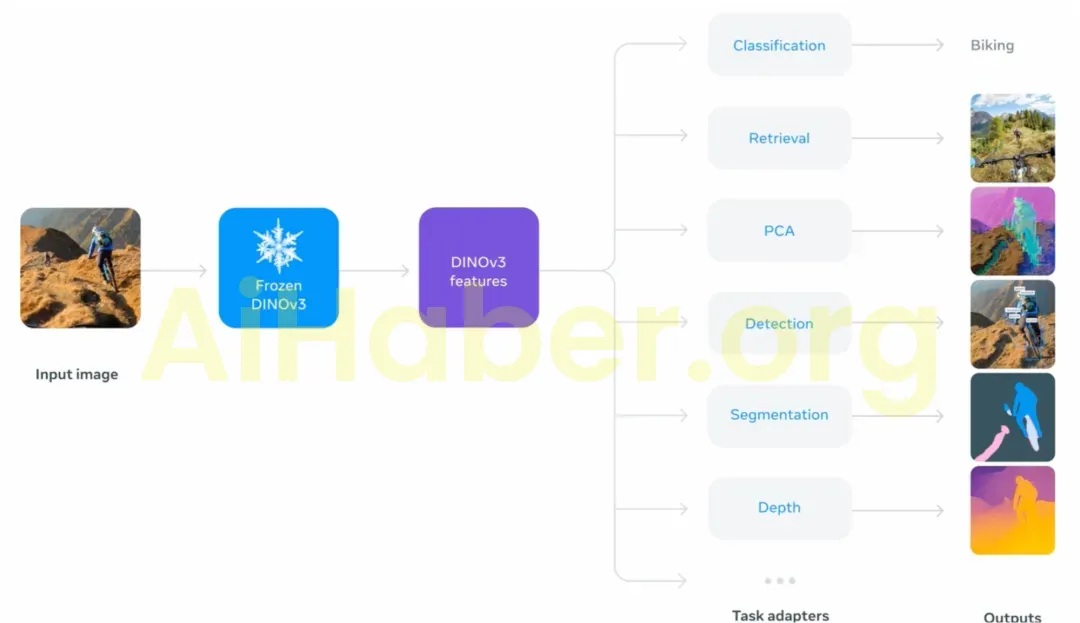
Model tarafından üretilen zengin ve yoğun özellikler, görüntüdeki her pikselin ölçülebilir özelliklerini veya karakteristiklerini yakalar ve kayan nokta vektörleri olarak temsil edilir. Bu özellikler, nesneleri daha ayrıntılı bileşenlere ayrıştırabilir ve hatta farklı örnekler ve kategoriler arasında genelleştirilebilir.
Bu güçlü yoğun gösterim yeteneği sayesinde Meta, çok az açıklama ile DINOv3 üzerinde hafif bir adaptör eğitebilir; sağlam yoğun tahmin sonuçları elde etmek için yalnızca az miktarda açıklama ve doğrusal bir modele ihtiyaç vardır.
Ayrıca, daha karmaşık bir kod çözücüyle birleştirildiğinde Meta, omurga ağını ince ayarlamadan nesne tespiti, anlamsal segmentasyon ve göreceli derinlik tahmini gibi uzun süredir devam eden temel görüş görevlerinde en son teknoloji performansına ulaşabileceğini göstermektedir.
Omurga ağında ince ayar yapmadan en son teknoloji performansına ulaşılabildiğinden, tek bir ileri geçiş aynı anda birden fazla görevi yerine getirebilir ve çıkarım maliyetlerini önemli ölçüde azaltabilir. Bu, genellikle aynı anda birden fazla görsel tahmin görevi gerçekleştirmeyi gerektiren uç uygulamalar için özellikle kritik öneme sahiptir.
Kolayca dağıtılabilen seri modeller
DINOv3’ü 7 milyar parametreye ölçeklendirmek, öz denetimli öğrenmenin (SSL) tüm potansiyelini ortaya koymaktadır. Ancak, birçok alt akış uygulaması için 7 milyar parametreli bir model pratik değildir. Topluluk geri bildirimlerine dayanarak Meta, çeşitli dağıtım senaryolarında araştırmacıları ve geliştiricileri desteklemek için farklı çıkarım hesaplama gereksinimlerini kapsayan bir model ailesi oluşturmuştur.
Meta, ViT-7B modelini damıtarak ViT-B ve ViT-L gibi daha küçük ama yine de mükemmel model varyantları elde etti ve bu da DINOv3’ün çoklu değerlendirme görevlerinde benzer CLIP tabanlı modelleri kapsamlı bir şekilde geride bırakmasını sağladı.
Meta ayrıca, farklı bilgi işlem kaynağı kısıtlamalarını karşılamak için ViT-7B’den damıtılmış bir dizi ConvNeXt mimari modeli (T, S, B ve L sürümleri) yayınladı. Meta ayrıca, topluluk içinde daha fazla geliştirme ve inovasyonu kolaylaştırmak için tüm damıtma hattını açık kaynaklı hale getirdi.
Meta’nın “dünyayı değiştirme” girişimi
Meta, DINOv2’nin büyük miktarda etiketlenmemiş veriyi kullanarak histopatoloji, endoskopi ve tıbbi görüntüleme gibi alanlardaki kuruluşların tanı ve araştırma çalışmalarını desteklediğini söyledi.
Uydu ve hava fotoğrafçılığı alanında, veri hacmi çok büyük ve yapı karmaşık olduğundan, manuel açıklama eklemek neredeyse imkânsızdır. Meta, DINOv3 teknolojisinden yararlanarak, bu yüksek değerli veri kümelerinin, çevre izleme, şehir planlama ve afet müdahalesi gibi alanlarda yaygın olarak uygulanabilen birleşik bir görsel omurga modelinin eğitilmesinde kullanılmasını sağlar.
DINOv3’ün çok yönlülüğü ve verimliliği, onu bu tür konuşlandırmalar için ideal bir seçim haline getiriyor; NASA’nın Jet Tahrik Laboratuvarı’nın (JPL) halihazırda DINOv2’yi kullanarak birden fazla görüş görevini hafif bir şekilde gerçekleştirebilen bir Mars keşif robotu inşa etmesi bunu gösteriyor.
DINOv3, gerçek dünyada şimdiden etkili olmaya başladı. Dünya Kaynakları Enstitüsü (WRI), orman kaybını ve arazi kullanımındaki değişiklikleri tespit etmek için uydu görüntülerini analiz etmek amacıyla DINOv3’ü kullanıyor. DINOv3’ün sağladığı artan doğruluk, iklim finansmanı dağıtımlarının otomasyonunu sağlıyor, işlem maliyetlerini düşürüyor ve özellikle küçük yerel kuruluşları desteklemek amacıyla restorasyon başarılarını daha doğru bir şekilde doğrulayarak fon dağıtımını hızlandırıyor.
Örneğin, DINOv2 ile karşılaştırıldığında, uydu ve hava görüntüleri kullanılarak eğitilen DINOv3, Kenya’nın bir bölgesinde ağaç gölgelik yüksekliği ölçümlerindeki ortalama hatayı 4,1 metreden 1,2 metreye düşürdü. Bu, WRI’nin binlerce çiftçiye ve koruma projesine verdiği desteği daha verimli bir şekilde artırmasını sağlıyor.
DINOv3 detayları hakkında daha fazla bilgi edinmek isteyen okuyucular orijinal makaleye başvurabilirler.

- Makale adresi: https://ai.meta.com/research/publications/dinov3/
- Hugging Face Adresi: https://huggingface.co/docs/transformers/main/en/model_doc/dinov3
- Blog adresi: https://ai.meta.com/blog/dinov3-self-supervised-vision-model/
Benzer Yazılar

Proteinler yüksek derecede konformasyonel esnekliğe sahiptir ve şekle uyum sağlama yetenekleri fonksiyonel özellikler açısından kritik...
İşinizin "değerli içeriği" AI tarafından boşaltılıyor. Anthropic'in en son raporu, sezgilere aykırı bir gerçeği ortaya...
