




















Gaz pedalına basarken ve AGI'yi koşarken uyarmak için kornaya basın: İlerideki uçuruma dikkat edin! Antropik...
MolErr2Fix: Büyük modellerin kimya dünyasında “hataları kabul etmeyi” öğrenmesine olanak tanıyan bir değerlendirme kriteri
Yazı Özetini Göster


Özet Büyük Dil Modelleri (LLM’ler) kimyasal bilişimin araştırma paradigmasını yeniden şekillendiriyor. Bununla birlikte, model tarafından oluşturulan kimyasal metinler genellikle “gramer açısından doğru ancak kimyasal olarak yanlıştır”. Görünüşte düzgün fakat güvenilmez olan bu çıktı, bilimsel araştırma senaryolarında ciddi yanılgılara neden olabilir. Bu makalede tanıtılan MolErr2Fix, LLM’nin kimyasal güvenilirliğini sistematik olarak değerlendiren ilk kıyaslama veri setidir. Modelin yalnızca “konuşulabilir” değil aynı zamanda “doğru konuşabilmesini” amaçlayan hata tespiti, yerelleştirme, yorumlama ve onarımdan oluşan dört aşamayı kapsar.
Araştırmanın Arka Planı: Dil Modellerinin “Kimyasal Yanılsaması”
GPT-4, Claude ve Gemini gibi büyük modellerin hızla gelişmesiyle birlikte, molekül başlığı oluşturma, reaksiyon tahmini ve ilaç tasarımı gibi görevlerde şaşırtıcı dil ve model öğrenme yetenekleri sergilediler. Ancak araştırmacılar çok geçmeden bu modellerin genellikle düzgün ve doğal moleküler açıklama metinleri ürettiğini ancak içeriklerinin bariz kimyasal hatalar içerdiğini keşfettiler.
Örneğin, bir molekülün SMILES yapısı göz önüne alındığında model şunları yapabilir:
-
İkame konumu veya fonksiyonel grubun yanlış değerlendirilmesi;
-
Ana yapı ile türevler arasındaki ilişkinin karıştırılması;
-
Ters stereokimya (R/S veya E/Z);
-
Kendi hatasını bile fark edemiyor.
Daha ciddi olan şey ise bu “kimyasal halüsinasyonların” genellikle geleneksel doğal dil değerlendirme göstergeleri tarafından tespit edilememesidir. BLEU ve ROUGE gibi puanlar, bilimsel gerçeklerin doğruluğundan ziyade esas olarak metin yüzeyi benzerliğini ölçer. Bir cümle, sözcük düzeyinde referans açıklamasına oldukça benzer olsa bile kimyasal olarak tamamen yanlış olabilir.
Makalenin işaret ettiği gibi, bu tür bir olay özellikle ilaç tanımı, reaksiyon mekanizması analizi ve malzeme özelliği tahmini gibi senaryolarda tehlikelidir. Bu nedenle modellerin “kimyasal anlama yeteneğini” ölçen yeni bir değerlendirme çerçevesine ihtiyacımız var.
MolErr2Fix: Kimyasal güvenilirlik için yeni bir değerlendirme paradigması
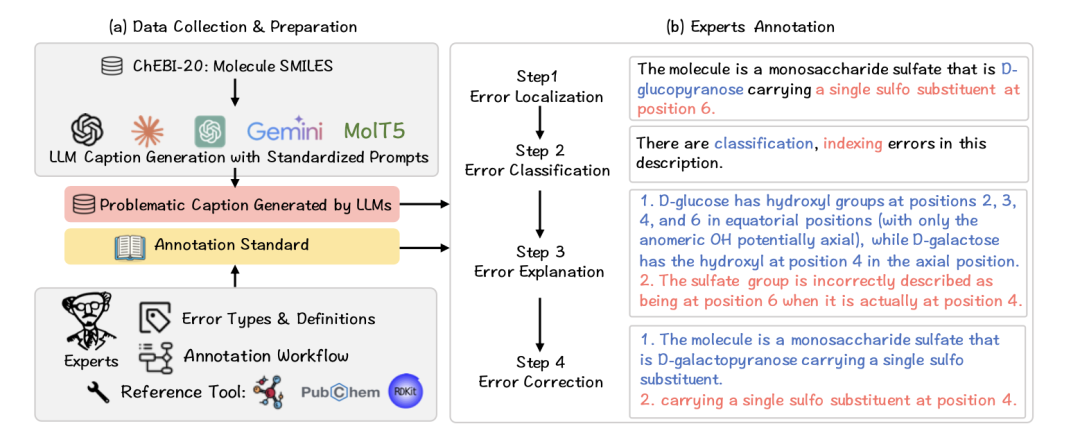
MolErr2Fix, kimyasal metin anlama ve düzeltmede dil modellerinin performansını sistematik olarak değerlendirmek için Carnegie Mellon Üniversitesi ve Hong Kong Bilim ve Teknoloji Üniversitesi tarafından ortaklaşa önerildi. Görevi tek bir metin üretiminden dört temel aşamadan oluşan bir kimyasal hata analizi zincirine dönüştürür:
-
Hata Tespiti
Metinde kimyasal hatalar olup olmadığını belirleyin ve bunları altı hata türüne göre sınıflandırın: fonksiyonel gruplar/ikame ediciler, kimyasal sınıflandırma, türev ilişkileri, stereokimya, kompozisyon sayımı ve numaralandırma konumlandırması.
-
Hata Yerelleştirmesi
Metin aralığını işaretleyerek belirli hatanın bulunduğu bölümü veya ifadeyi belirtin. Değerlendirme göstergelerinde IoU (Birleşim Üzerinden Kesişme) ve Recall@IoU≥0,5 kullanılır.
-
Hata Açıklaması
Modelin “neden yanlış olduğunu” kimya dilinde açıklamasına izin verin. Bu bağlantı, modelin sembolik akıl yürütmeyi mesleki bilgiyle birleştirme becerisine sahip olmasını gerektirir.
-
Hata Düzeltme
Açıklamanın tamamını yeniden yazmak yerine, modelin hatalı bölümü değiştirmesi ve kimyasal olarak doğru bir sürüm çıkarması gerekir.
“Keşiften düzeltmeye” kadar olan bu zincirleme süreç, bilimsel araştırmacıların makaleleri incelemesi ve deneysel raporları gözden geçirmesi şeklindeki gerçek süreci simüle eder. MolErr2Fix yalnızca modelin oluşturulma yeteneğini test etmekle kalmıyor, aynı zamanda mantıksal tutarlılığını ve bilimsel akıl yürütme yeteneğini de test ediyor.
Veri yapısı: Manuel hassas etiketlemenin hata örneği sistemi
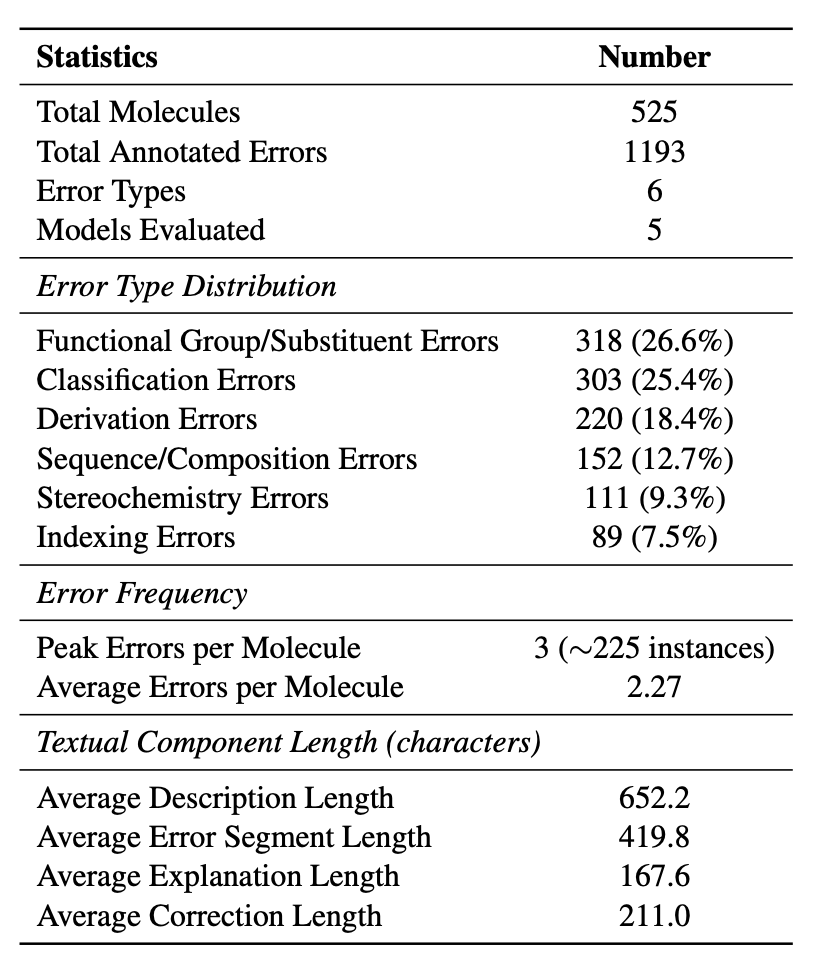
MolErr2Fix veri seti toplam 525 molekül ve 1.193 hassas etiketleme hatası örneği içeriyor. Her örnek, organik kimya geçmişine sahip üç uzman tarafından bağımsız olarak açıklanmaktadır. Ek açıklamalar şunları içerir:(Hata türü, hata yeri, hata açıklaması, doğru düzeltme)
Bu moleküler örnekler, şekerler, steroidler, aromatik bileşikler, esterler ve aminler gibi yaygın yapısal türleri kapsayan ChEBI-20 veri tabanında 100’den az atoma sahip moleküllerden türetilir. Ek açıklama süreci sırasında araştırmacılar kasıtlı olarak çeşitli “dilsel olarak doğru ancak kimyasal olarak yanlış” açıklama örnekleri sundular. Örneğin:
-
“6. pozisyonda bir sülfo ikame edicisi taşıyan bir D-glikopiranoz”, yüzeyde dil bilgisi açısından doğrudur, ancak stereo konfigürasyonun açıklamasından yoksundur.
-
“Metil (17E)-pregna-4,17-dien-21-oat olan bir steroid ester” doğru addır, ancak kritik keton işlevselliğini kaçırmaktadır.
Bu “tuzak örnekleri”, MolErr2Fix’in temel test zorluğunu oluşturur ve modeli basit dil eşleştirmesi yerine yapısal düzeyde kimyasal anlayışa sahip olmaya zorlar.
Deneysel Tasarım: Büyük Modellerin Kimyasal Denemeye Alınması
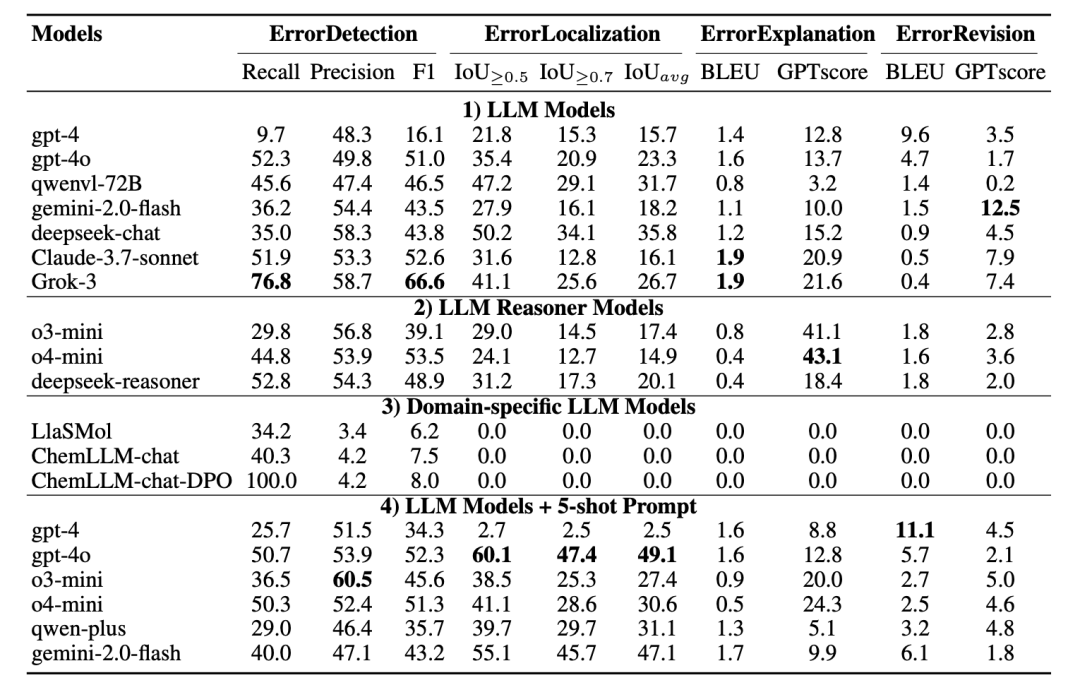
Araştırma ekibi GPT-4o, Claude-3.7-Sonnet, Gemini-1.5-Pro, LlaSMol ve ChemLLM dahil olmak üzere birçok ana modeli değerlendirdi. Deney, birkaç adımlık yönlendirmeden oluşan birleşik bir çerçeve benimser ve her görev bağımsız olarak değerlendirilir.
Temel bulgular aşağıdaki gibidir:
-
Tespit edilmesi kolay
Onarım zorluğu: Hata tespit görevlerinde bazı modeller F1≈%66’ya ulaşabilir; ancak onarım görevlerinde BLEU puanı genellikle 2’den düşüktür, bu da uzmanlarla tutarlı düzeltme sonuçları elde etmeyi neredeyse imkansız hale getirir.
-
Konumlandırma performansı değişiklik gösterir
Model, bariz hataları (işlevsel grup kategorileri gibi) bulma konusunda yüksek bir doğruluğa sahiptir, ancak sayısal sayılar ve ikame konumları içeren metinlerde doğruluk keskin bir şekilde düşer.
-
Açıklama görevleri akıl yürütme eksikliklerini ortaya çıkarır
Model, “bunun işlevsel bir grup hatası olduğunu” tanımlayabilse de, genellikle “hidroksil grubunun bu bölgede neden mevcut olamayacağını” açıklayamaz.
-
Restorasyon misyonu neredeyse tamamen yok edildi
Model, değiştirilmiş metin oluştururken tutarlılıktan yoksundur ve hatta “daha fazla hata düzeltilir” olgusu ortaya çıkar.
Genel sonuçlar, mevcut LLM’nin hala temel olarak kimyasal dil görevlerinde yüzey deseni tanımaya dayandığını ve sistematik kimyasal sembol akıl yürütme ve kendi kendine hata teşhis yeteneklerinden yoksun olduğunu göstermektedir.
Analiz ve Tartışma: Kimya neden bu kadar zor?
MolErr2Fix’in sonuçları, Yüksek Lisans kimyasal muhakemesindeki zorlukların üç ana kaynağını ortaya koymaktadır:
-
Mesleki bilginin incelmesi
Moleküler yapı kuralları (halka sistemi numaralandırması ve ikame sırası gibi) genel derlemde son derece nadirdir ve ders kitaplarında bile sistematik olarak ifade edilmemiştir.
-
Semboller örtülülüğü temsil eder
SMILES’ın kiralite bilgisi yalnızca “@” sembolüyle örtülü olarak ifade edilir ve modelin, bitişiklik sırası ve atomik öncelik aracılığıyla yapısal ilişkiyi çıkarması gerekir. Bu tür bilgilerin metin tabanlı bir Transformer mimarisiyle yakalanması son derece zordur.
-
İsim belirsizliği ve anlam kayması
Kimyasal isimlendirme sistemi birden fazla eşdeğer ifadeye izin verir (IUPAC ve ortak adlar gibi), ancak modeller genellikle bunları farklı kavramlar olarak ele alır ve bu da anlamsal karışıklığa yol açar.
Bilişsel düzeyden bakıldığında, Yüksek Lisans’ın dil modelleme hedefleri ile kimyasal bilginin sembolik mantığı arasında doğal bir gerilim vardır: dil “sürekli anlamsal akışı” takip ederken, kimyasal bilgi “ayrı yapısal mantığı” vurgular. MolErr2Fix, modeli ikisi arasında bir köprü kurmaya zorlamak için tasarlanmıştır.
6. Uygulama değeri ve geleceğe yönelik beklentiler
MolErr2Fix’in önemi yalnızca değerlendirmede değil, aynı zamanda kimya alanında LLM’nin “güvenilir zekasını” teşvik etmede de yatmaktadır.
(1) Modelin iyileştirilmesi için yön sağlayın
Araştırmacılar MolErr2Fix’i bir eğitim hedefi olarak kullanabilir ve “algılama → yorumlama → onarım” kapalı döngü optimizasyonunu elde etmek için öz yansıtma mekanizmasını takviyeli öğrenme (RLHF) ile birleştirebilir.
(2) Çok modlu görev genişletmeyi destekleyin
Gelecekteki sürümler, çapraz mod hata tespitini gerçekleştirmek için moleküler yapı diyagramlarının (2D/3D) ve anlamsal metnin ortak girdisini sunmayı planlamaktadır.
(3) Kimyasal NLP standardizasyonunu teşvik edin
MolErr2Fix, kimyasal doğal dil işleme konusunda daha sonraki araştırmalar için birleşik değerlendirme özellikleri sağlamak amacıyla evrensel bir hata sınıflandırma sistemi kurmuştur.
(4) Gerçek bilimsel araştırma senaryolarında güvenilir bir asistan
İlaç geliştirme ve otomatik literatür taramasında, eğer Yüksek Lisans bu tür değerlendirmeleri geçebilirse, çıktı sonuçlarının daha “doğrulanabilir” ve “izlenebilir” olduğu anlamına gelir.
Sonuç ve görünüm
MolErr2Fix basit bir değerlendirme görevi değil, yeni bir araştırma konseptidir:Dil modellerinin hataları bilim adamları gibi ele almasına izin verin.
Modelin yalnızca sorunları tanımlamasını değil, aynı zamanda ilkeleri açıklığa kavuşturmasını ve makul değişiklikler önermesini de gerektirir. Bu sistem aracılığıyla, yalnızca külliyatı okumak yerine, modelin kimyasal anlambilimi gerçekten anlayıp anlamadığını ölçebiliyoruz.
Gelecekte yazar ekibi aşağıdaki yönlerde ilerlemeye devam etmeyi planlıyor:
-
Makromolekülleri ve peptit sistemlerini kapsayacak şekilde moleküllerin boyutunu ve kategorisini genişletin;
-
Grafik sinir ağına dayalı bir yardımcı doğrulama modülünün tanıtılması;
-
Laboratuvar senaryosuna daha yakın bir “çok yönlü hata onarım diyaloğu” görevi oluşturun.
Makalenin sonuç bölümünde söylediği gibi:
“MolErr2Fix günümüzün sınırlarını haritalandırıyor ve bilimsel açıdan güvenilir Yüksek Lisans’lara giden yolu çiziyor.” – Sadece günümüz modellerinin sınırlarını ortaya çıkarmakla kalmıyor, aynı zamanda “bilimsel açıdan güvenilir dilsel zekaya” giden yolu da işaret ediyor.
Kağıt bilgileri ve açık kaynak kaynakları
Paper Wu, Yuyang, Ye, Jinhui, Zhang, Shuhao, Dai, Lu, Bisk, Yonatan, Isayev, Olexandr.MolErr2Fix: Modüler Hata Tespiti, Yerelleştirme, Açıklama ve Revizyon Yoluyla Kimyada LLM Güvenilirliğinin Kıyaslanması.EMNLP 2025 (Sözlü).
Veri ve kod
-
GitHub: https://github.com/HeinzVonHank/MolErr2Fix
-
Veri kümesi: https://huggingface.co/datasets/YoungerWu/MolErr2Fix
İçerikte yer alan resimler telif hakkı sorunları içeriyorsa lütfen bunları silmek için zamanında bizimle iletişime geçin.
Benzer Yazılar
Hong Kong Üniversitesi bünyesinde geliştirilen DeepTutor, bireyselleştirilmiş öğrenme süreçlerini desteklemek amacıyla tasarlanmış yenilikçi bir açık kaynak...

Açık sözcük dağarcığı semantik segmentasyonunda görsel dil modelleri (VLM) için özel olarak tasarlanmış yeni bir...
