Yeni yayınlanan Claude Opus 4.1 yapay zekâ modeli kullanılmaya değer mi? Kodlama, araştırma ve güvenlikteki gelişmelerini...
Yazı Özetini Göster

OpenAI son zamanlarda birçok kez farklı yeni modeller sundu ve bu modellerin hiçbiri kamuoyuna açıklanmadı. Geçen hafta OpenAI, o3 ile ilgili olan ancak kamuoyuna açıklanmayan iki yeni modeli açıkladı. Bunlardan birinin “gizli GPT-5” olduğundan şüphelenilirken, diğeri hem yapay zeka modelleri hem de insan oyuncuların katıldığı bir programlama dünya şampiyonasında ikinci oldu.
Sahneye çıkan en son model, OpenAI’nin “Uluslararası Matematik Olimpiyatları’nda (IMO) altın madalya kazandığını” iddia ettiği bir model. Her yıl Uluslararası Matematik Olimpiyatları’na (IMO) katılan öğrenciler, dünyanın dört bir yanından son derece yetenekli genç matematik yeteneklerinden oluşuyor. Bu yıl ise, daha güçlü bir yapay zeka modeli grubunun zorluklarıyla karşı karşıya kaldılar. Google DeepMind’ın kurucu ortağı ve CEO’su Demis Hassabis de az önce Gemini Deep Think’in IMO’da altın madalya kazandığını duyurdu.
Ancak her ikisi de altın madalyayı kazandıklarını açıklasa da, değerlendirmeler oldukça farklıydı. Birçok internet kullanıcısı, “OpenAI dikkat çekmek için her şeyi yapar. Resmi bir puan, sabır ve net bir sonuç yok.” dedi. “Google DeepMind’ın performansı örnek teşkil ediyor ve onu çok takdir ediyorum.”
1- OpenAI modeli bence Google’a mı kaybediyor?
Hassabis’in sözleriyle “inanılmaz bir ilerleme”. Google, özel olarak optimize edilmiş matematiksel yapay zekasının altı sorudan beşini doğru yanıtladığını söyledi. Google, bundan önce Temmuz 2024’te AlphaProof ve AlphaGeometry 2 modellerinin IMO’da gümüş madalyaya eşdeğer bir başarı elde ettiğini iddia etmişti; ancak Google’ın sistemi, her bir problemi çözmek için insan sınırı olan 4,5 saat yerine üç güne kadar zaman harcadı ve soruları resmi matematik diline çevirmek için insan yardımı gerektirdi.
Ancak, birkaç gün önce OpenAI araştırmacısı Alexander Wei, şirketin geliştirmekte olduğu yeni bir yapay zeka modelinin IMO’da altın madalya kazandığını duyurdu. Bu, her yıl insan yarışmacıların yalnızca %9’undan azının ulaşabileceği bir seviye. Bu deneysel yapay zeka modelinin araştırma ekibine Alexander Wei liderlik ediyor ve Sheryl Hsu ile Noam Brown destek veriyor.
Modelin, yarışmadaki altı kanıta dayalı soruyu çözerken insan yarışmacılarla aynı kısıtlamalara tabi tutulduğu bildirildi: her sınav 4,5 saat sürdü ve internet veya hesap makinesi kullanımına izin verilmedi. OpenAI, bu başarının, özel teorem ispatlama sistemlerine dayanan ve genellikle insan zaman sınırlarını aşan önceki yapay zeka Matematik Olimpiyatı sorularından farklı olduğunu belirtti. Şirket, modelinin soruları düz metin olarak işlediğini ve özel olarak oluşturulmuş bir matematik sistemi yerine standart bir dil modeli gibi çalışarak doğal dil ispatları ürettiğini belirtti.
Ayrıca, OpenAI başlangıçta bu yarışmaya katılmayı planlamamış, ancak testte olumlu sonuçlar gördükten sonra kendi araştırma sonuçlarını değerlendirmeye karar vermiştir. Uluslararası Matematik Olimpiyatı organizatörleri tarafından hazırlanan yeni soruların aynı anda birden fazla yapay zeka şirketiyle paylaşılacağı ve OpenAI’nin de bu soruları aldığı anlaşılmaktadır. Sonuçları doğrulamak için, her bir çözüm OpenAI tarafından organize edilen üç eski Uluslararası Matematik Olimpiyatı madalyalısından oluşan bir jüri tarafından kör olarak incelenmiş ve yalnızca oybirliğiyle karar alanlar başarılı kabul edilmiştir.
OpenAI, Uluslararası Matematik Olimpiyatı organizatörlerinin yapay zekâ şirketlerinden sonuçların açıklanmasını 28 Temmuz’a ertelemelerini istemesine rağmen haberi yayınladı. Ancak, sürece aşina olan birkaç kaynak, OpenAI’nin Uluslararası Matematik Olimpiyatı’nda kendi sonuçlarını puanlaması nedeniyle şirketin açıklamasının meşruiyetinin sorgulanabilir olabileceğini söyledi. OpenAI, ilgili kanıt sürecini ve puanlama kriterlerini kamuoyunun incelemesine sunmayı planlıyor.
DeepMind’ın Süper Akıl Yürütme Ekibi’nin lideri Thang Luong’a göre, IMO organizatörlerinin resmi bir puanlama standardı var, ancak bu standart kamuoyuna açıklanmıyor. Bu standarda göre değerlendirilmediği takdirde, madalya sahipliği iddiası geçersiz sayılacak. “Bir puan düşüldükten sonra, altın madalya değil, gümüş madalya kazanılacak.”
Otomatik puanlama sonuçlarına ilişkin tartışmaların yanı sıra, OpenAI’nin ödülleri önceden duyurması ve Uluslararası Matematik Olimpiyatı ile gizlilik anlaşmasını ihlal etmesi de IMO topluluğunu kızdırdı.
Yarışmaya katılan yapay zeka şirketi Harmonic, 20 Temmuz’da X’te yayınladığı bir gönderide şunları açıkladı: “IMO Yönetim Kurulu, yarışmaya katılan diğer büyük yapay zeka şirketleriyle birlikte, sonuçlarımızı 28 Temmuz’a kadar yayınlamamamızı istedi.” Hassabis ayrıca OpenAI’nin altın madalyayı sosyal medyada erken duyurmasını da eleştirdi: “Uluslararası Matematik Olimpiyatları Komitesi’nin, tüm yapay zeka laboratuvarlarının sonuçlarını ancak resmi sonuçlar bağımsız uzmanlar tarafından doğrulandıktan ve öğrencilere hak ettikleri övgü için adil bir muamele yapıldıktan sonra paylaşabileceği yönündeki ilk talebine saygı duyuyoruz.”
2- Yeni model “o3 Alpha”nın sessiz sedasız piyasaya sürüleceği düşünülüyor
Geçtiğimiz hafta bir internet kullanıcısı, OpenAI’nin WebArena’da “o3-alpha-responses-2025-07-17” adlı yeni bir modeli test ettiğini açıkladı. Bu model “Anonymous-Chatbot” ismiyle karşımıza çıkıyor.
Jimmy Apples, web geliştirme konusunda yeni modeli Gemini 2.5 pro ile karşılaştırarak, “gizemli tarzda bir web sitesi yap” komutunu kullandı ve şu yorumu yaptı: “Bu şey çok güçlü, harika.”
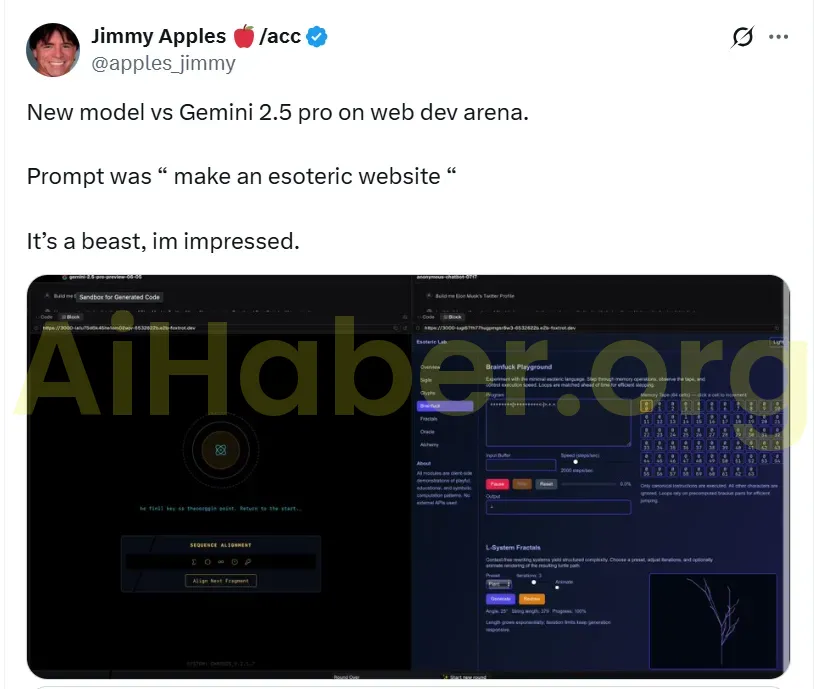
Şu anda “o3 Alpha” web geliştirme test platformundan kaldırıldı. Sadece 5-6 saat kadar çevrimiçi kaldığı bildiriliyor. Quazar Alpha, son testlerden kısa bir süre sonra resmi olarak yayınlanmıştı, bu nedenle bu yeni programlama modeli de önümüzdeki birkaç hafta içinde tanıtılabilir.
Önemli olan, OpenAI’nin son derece güçlü programlama yeteneklerine sahip bir modele sahip olmasıdır. OpenAI CEO’su Sam Altman bunu daha önce ima etmişti: Şubat 2025’te, şirketin dünyanın en iyi 50 programcısı arasında yer alan bir modele sahip olduğunu ve 2025 yılı sonuna kadar “insanüstü seviyede” bir programlama modeli başlatmasının beklendiğini belirtmişti. Ve şimdi bu model, bu hedefe çok yakın görünüyor.
Jimmy Apples’ın yanı sıra, birkaç model kullanıcısı daha “o3 Alpha” hakkında olumlu yorumlarda bulundu. Bazıları da şöyle düşündü: “Bu GPT-5, o3 alpha kılığına mı girmiş?”
Ancak, şirketin bir sonraki büyük yapay zeka modeli GPT-5’in “yakında çıkacağını” doğruladığını belirtmek önemlidir. Şirket, “teknolojinin devam edeceğini, ancak bu düzeyde kabiliyete sahip modellerin kısa vadede piyasaya sürülmeyeceğini” de belirtti. Açıkça görülüyor ki, OpenAI bu özel deney için çok fazla bilgi işlem kaynağı (ki bu da yüksek bir maliyet anlamına geliyor) yatırdı ve bu ölçekte bir bilgi işlemin yakın gelecekte tüketiciye yönelik yapay zeka modellerinde ortaya çıkması pek olası değil.
3 –Gizemli Akıl Yürütme Modeli Açık Yarışması: 2.lik
Geçtiğimiz hafta tesadüfen, eski OpenAI çalışanı Przemysław Dębiak, Tokyo’da düzenlenen 2025 AtCoder World Tour Finalleri Heuristic Yarışması’na katıldığında, sadece programlama becerilerinde birden fazla insan yarışmacıyla yarışmakla kalmadı, aynı zamanda OpenAI’dan olduğu söylenen “OpenAIAHC” kod adlı, o3’e benzer yeni bir özelleştirilmiş simüle edilmiş akıl yürütme modeliyle de yarıştı.
Bu yarışmada, katılımcılardan 10 saat içinde karmaşık bir optimizasyon problemini çözmeleri istendi ve ardından performanslarına göre puanlandırıldılar. Katılımcılar, problemi çözmek için AtCoder platformunda bulunan herhangi bir programlama dilini kullanabildiler, ancak tamamen aynı donanım özelliklerini kullandılar ve her kod gönderimi arasında beş dakika beklemeleri gerekiyordu. “Psyho” adıyla yarışan Dębiak, 1.812.272.588.909 puanla liderlik tablosunun zirvesine yerleşti ve 1.654.675.725.406 puan alan bir yapay zekayı geride bırakarak ikinci oldu.
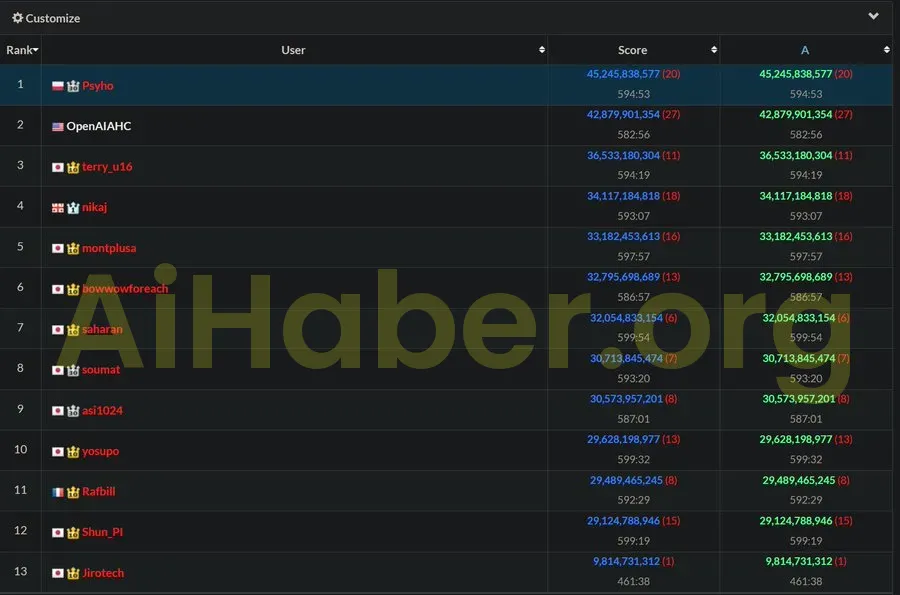
“Çok yorgunum. Son üç gündür 10 saat uyudum ve zar zor ayakta duruyorum.” Dębiak, X’teki başarısını gururla “İnsanlık kazandı (şimdilik!)” diyerek kutlarken, yarışmanın kendisini çok yorduğunu da itiraf etti.
OpenAI, yeni modelinin gümüş madalyasından oldukça memnun görünüyor. Şirket sözcüsü bir röportajda, “o3 gibi modeller programlama/matematik yarışmalarında ilk 100’e girebilir, ancak bildiğimiz kadarıyla bu, en iyi programlama/matematik yarışmalarından birinde ilk üçe girdiği ilk sefer. AtCoder gibi yarışmalar, modellerin yeteneklerini test etmemize olanak sağlıyor; stratejik olarak akıl yürütüp yürütemeyeceklerini, uzun vadeli planlar yapıp yapamayacaklarını ve insanlar gibi deneme yanılma yoluyla çözümleri geliştirip geliştiremeyeceklerini görmemizi sağlıyor.” dedi.
Bu yarışma, bir yapay zeka modelinin bir programlama etkinliğinde doğrudan insan programcılarla yarıştığı ilk yarışmaydı ve yapay zeka kazanmasa da ikinci olması etkileyiciydi. Bu, insan programcıların geleceği için pek de iyiye işaret olmayabilir. Çünkü programcıların becerileri kaçınılmaz olarak gelişmeye devam edecek olsa da, yapay zekanın hızla gelişmesi, yapay zeka modellerinin benzer yarışmalarda zirveye yerleşmesinin çok da uzun sürmeyeceği anlamına gelebilir.
Referans Bağlantıları:
https://www.youtube.com/watch?v=BZAi9h9uCX4
Benzer Yazılar
Yapay zekâ teknolojilerinin küresel çapta hızla geliştiği bir dönemde, Çin merkezli yenilikçi şirketler de bu...

Son günlerde teknoloji gündeminde en çok konuşulan ürünlerden biri AI Key oldu. 89 dolara satılan...