





















MIT'nin 300'den fazla yapay zeka projesi üzerine yaptığı araştırmaya, 52 kuruluşla yapılan görüşmelere ve 153...
Yazı Özetini Göster






1.3 metre boyundaki Little Potato isimli robot, ipeksi bir pürüzsüzlükte katmanlama yapabiliyor.
Yanlış anlamayın, bu Yushu G1 henüz NBA draftına katılmayacak, ancak yeni kazandığı “gerçek dünya basketbolu” becerisiyle, “köy BA”sının ilk 11’ine girmesi uzun sürmeyecek.
Hong Kong Bilim ve Teknoloji Üniversitesi’nden bir araştırma ekibi tarafından geliştirilen bu robotun, gerçek dünya senaryosunda basketbol hareketleri yapabilen dünyanın ilk robot demosu olduğu bildiriliyor.
Ekip henüz tüm teknik detayları açıklamasa da, robotların “basketbol oynamasını” sağlamaya yönelik önceki çalışmalarına dayanarak, bunun önceki araştırmalarına göre daha da gelişmiş bir çalışma olduğu düşünülüyor.
Şimdi daha yakından bakalım.
SkillMimic-v2
SIGGRAPH 2025 SkillMimic -V2: Seyrek ve Gürültülü Gösterimlerden Sağlam ve Genelleştirilebilir Etkileşim Becerilerini Öğrenmek .
SkillMimic-V2, etkileşimli sunum takviyeli öğrenmede (RLID) seyrek, gürültülü ve yeterince kapsanmayan sunum yörüngelerinin zorluklarını çözmeyi amaçlamaktadır.
Dikişli yörünge grafiği (STG) , durum geçiş alanı (STF) ve uyarlanabilir yörünge örneklemesi (ATS) gibi tekniklerin tanıtılmasıyla , düşük kaliteli veri koşulları altında hem sağlam kurtarma hem de beceri transferi yeteneklerine sahip karmaşık bir etkileşim stratejisi başarıyla eğitildi.
Günümüzde hareket yakalama gibi yöntemlerle toplanan verilerin genellikle şu dezavantajları bulunmaktadır:
-
Seyrek: Demo verileri yalnızca sınırlı sayıda beceri çeşidini kapsıyor ve beceriler arasında geçiş yörüngeleri bulunmuyor. -
Bağlantısız: Farklı beceri segmentleri bağımsızdır ve doğal bağlantılardan yoksundur. -
Gürültü: Veriler fiziksel olarak mümkün olmayan durumlar veya hatalar (el ile nesne arasında kırpma veya temas pozisyonunda sapmalar gibi) içerir ve bu da ince manipülasyon görevlerinde ciddi eğitim başarısızlıklarına yol açabilir.
Bu hatalı veriler, beceri çeşitliliğinin ve geçişlerinin tüm yelpazesini yakalamada başarısız oluyor.
Ancak, doğrudan daha iyi veriler toplamak yerine, çalışma, gösteri verilerinin seyrek ve gürültülü olmasına rağmen, fiziksel olarak sonsuz sayıda uygulanabilir yörüngenin olduğunu savunuyor .
Bu potansiyel yörüngeler doğal olarak farklı beceriler arasında köprü kurabilir veya gösteri devletinin mahallesinden ortaya çıkabilir.
Bu, olası beceri değişimleri ve geçişleri için sürekli bir alan yaratır ve bu eksik gösterim verilerini kullanarak düzgün, sağlam politikaların eğitilmesine olanak tanır.
Yukarıdaki anlayışa dayanarak, çalışma bu potansiyel yörüngeleri keşfetmek ve öğrenmek için üç temel adım önermektedir:
- Birleştirilmiş Yörünge Grafiği (STG) : Beceriler arasındaki bağlantı sorunlarını (top sürmeden şuta geçiş gibi) gidermek için algoritma, farklı gösteri yörüngeleri arasında benzer durumları arar. İki farklı becerinin yörüngelerinde benzer durumlar bulunursa, bir bağlantı kurulur ve ara geçiş kareleri maskelenir. Bu, politikanın orijinal verilerde bulunmayan beceri geçişlerini öğrenmesini sağlayan makroskobik bir grafik yapısı oluşturur.
- Eğitim için Durum Geçiş Alanı (STF) kullanılır. Referans yörüngesindeki belirli bir noktadan başlamak yerine, komşuluğundan rastgele örneklenmiş durumlarla başlatılır. Komşuluktaki herhangi bir örneklenmiş durum için, referans yörüngesindeki tüm durumlarla benzerliği hesaplanarak en uygun hedef bulunur. Başlangıç noktası hedef noktadan uzaksa, algoritma N adet maskelenmiş durum ekler. Bu durumlar ödül sağlamaz, ancak zaman tamponu görevi görerek, RL politikasının sapmış durumlardan referans yörüngesine nasıl “döneceğini” öğrenmesini ve böylece kurtarılabilir bir “alan” oluşturmasını sağlar.
- Uyarlanabilir Yörünge Örneklemesi (ATS) : Bu, örnekleme olasılığını, belirli bir yörünge segmentindeki mevcut politikanın performansına (ödül değeri) göre dinamik olarak ayarlar. Daha düşük ödüllü (öğrenmesi daha zor) segmentlerin örneklenme olasılığı daha yüksektir. Bu, uzun dizilerdeki yerel arızalar nedeniyle tüm zincirin kopması sorununu çözer.
Sonuç olarak, becerileri aktarma ve genelleme yeteneği, başlangıçta hiçbir beceri aktarımı veya hata kurtarma içermeyen seyrek gösterilerin çok ötesine geçerek daha verimli beceri öğrenimi ve genellemesi sağlar.
Örneğin bir simülasyon ortamında (Isaac Gym), robot rahatsız edilse bile yine de bir turnike atışı yapabilir.
Ayrıca top sürme ve şut çekme arasında beceri geçişlerine de olanak tanır.
Yapılan deneyler, SkillMimic-V2’nin önceki SOTA (SkillMimic) yöntemine kıyasla zor becerilerin (örneğin Layup) başarı oranını %0’dan %91,5’e çıkardığını gösteriyor . Beceri Başarı Oranı (TSR) da %2,1’den %94,9’a fırladı .
SkillMimic
SkillMimic-V2—— SkillMimic: Gösterilerden Basketbol Etkileşimi Becerilerini Öğrenmek
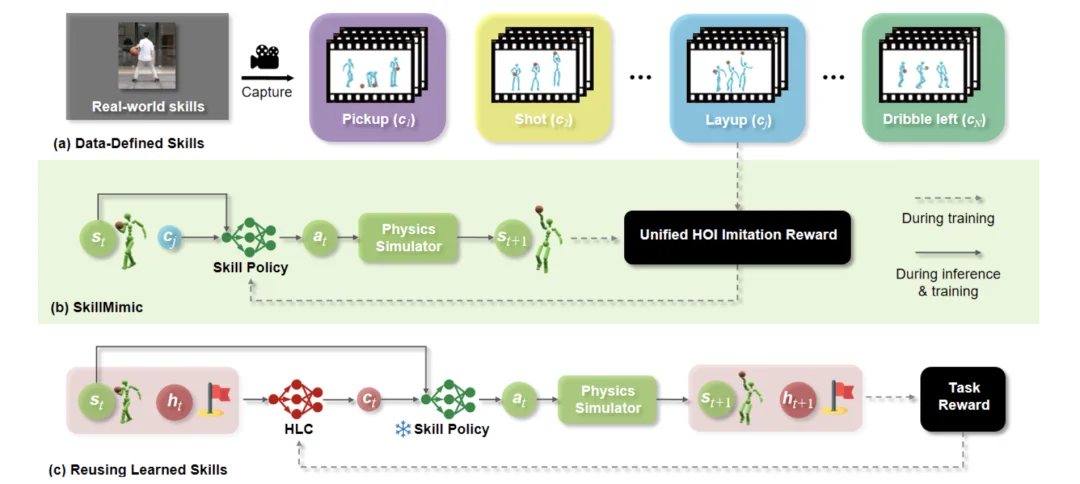
SkillMimic , karmaşık manuel ödül tasarımına dayanan ve birleşik bir çerçeve içinde çeşitli becerilerde ustalaşmayı zorlaştıran fizik tabanlı insan-nesne etkileşimindeki (HOI) geleneksel yöntemlerin zorluklarını ele almayı amaçlamaktadır .
Birleşik HOI taklit ödülü ve temas grafiği ve hiyerarşik beceri yeniden kullanımı gibi teknolojilerin tanıtılmasıyla , tek bir ödül yapılandırması altında hem hassas temas kontrolü hem de uzun vadeli görev kombinasyonu yeteneklerine sahip genel bir etkileşim stratejisi başarıyla eğitildi.
Araştırma hattı üç bölümden oluşmaktadır:
- Öncelikle, büyük ölçekli bir insan-bilgisayar etkileşimi (HOI) spor veri seti oluşturmak için gerçek basketbol becerileri verilerini topluyoruz.
- İkinci olarak, ilgili HOI verilerini taklit ederek etkileşimli becerileri öğrenmek üzere bir beceri stratejisi eğitilir. Çeşitli HOI durum geçişlerini taklit etmek için birleşik bir HOI taklit ödül mekanizması tasarlanmıştır.
- Son olarak, üst düzey bir denetleyici (HLC), son derece basit görev ödülleri kullanırken karmaşık görevleri ele almak için öğrenilen becerileri yeniden kullanmak üzere eğitilir.
SkillMimic yönteminin anahtarı şudur:
- Birleşik HOI Taklit Ödülü : Her beceri için ayrı ödüller tasarlamak yerine, HOI veri setini taklit ederek tüm becerilerin öğrenilmesini sağlayacak evrensel bir ödül yapılandırması tasarlanmıştır.
- Hiyerarşik Öğrenme Mimarisi : Alt Katman: Etkileşimli Beceri Politikası (IS Politikası): SkillMimic çerçevesi aracılığıyla çeşitli temel etkileşimli becerileri (top sürme ve smaç gibi) öğrenir. Üst Katman: Üst Düzey Kontrolcü (HLC): Uzun vadeli karmaşık görevleri (ardışık gol atma gibi) tamamlamak için öğrenilen IS politikasını yeniden kullanmak ve birleştirmek üzere üst düzey bir politika eğitir.
- Veri odaklı yaklaşım : İki veri seti oluşturuldu: BallPlay-V (video tahminine dayalı) ve BallPlay-M (optik hareket yakalamaya dayalı, daha yüksek doğrulukla), yaklaşık 35 dakikalık çeşitli basketbol etkileşimi verisi içeriyor.
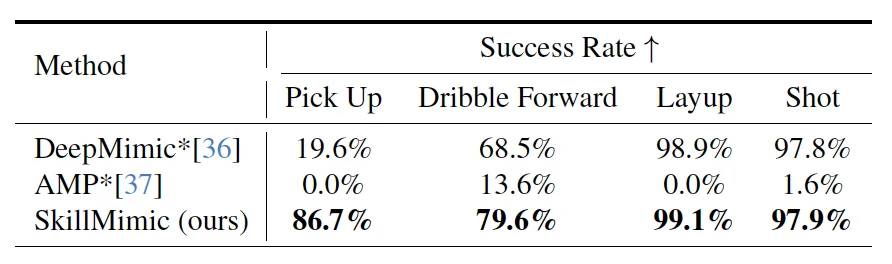
Deneyler, SkillMimic’in aynı konfigürasyonu kullanarak birden fazla basketbol becerisi stilini (top sürme, turnike, şut atma vb.) öğrenebildiğini ve DeepMimic ve AMP’ye göre önemli ölçüde daha yüksek bir başarı oranına sahip olduğunu göstermektedir.
Yapılan gösteride, simüle edilen ortamda robotun, topu daireler çizerek sürmek gibi ileri seviyede beceriler sergileyebildiği görülüyor.
PhysHOI
SkillMimic yazarlarının çalışmalarına bakarsanız, 2023 yılı gibi erken bir tarihte, PhysHOI: Dinamik İnsan-Nesne Etkileşiminin Fizik Tabanlı Taklidi adlı makalenin , simülasyondaki robotların gösterilere dayalı olarak basketbol becerilerini öğrenmesini sağlamayı denediğini göreceksiniz.

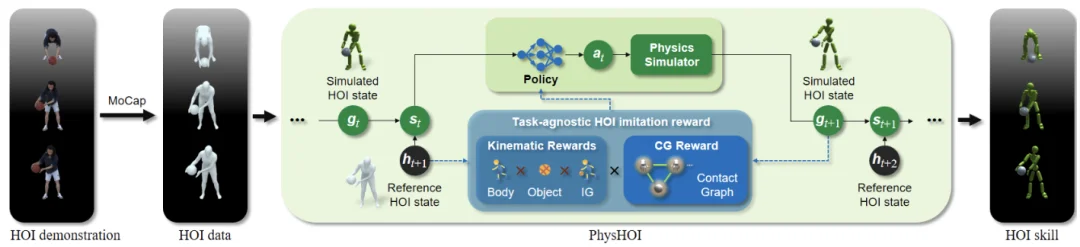
Bunu başarmak için PhysHOI , o dönemdeki fiziksel simülasyona dayalı dinamik bir insan-nesne etkileşimi (HOI) taklit öğrenme çerçevesi önerdi.
Basitçe ifade etmek gerekirse, referans HOI verileri verildiğinde, mevcut simüle edilmiş HOI durumu ve referans HOI durumu birlikte politika modeline girilir.
Politika, bir eylem çıktısı verir ve bir fizik simülatörü aracılığıyla bir sonraki simüle edilmiş HOI durumunu oluşturur. Ardından, kinematik ödül ağırlıklandırılır ve temas yakalama (CG) ödülüyle birleştirilir ve politika, beklenen getiriyi en üst düzeye çıkarmak için optimize edilir.
Yukarıdaki işlemi, yakınsama sağlanana ve referans verilerdeki HOI becerisi yeniden üretilebilene kadar tekrarlayın.
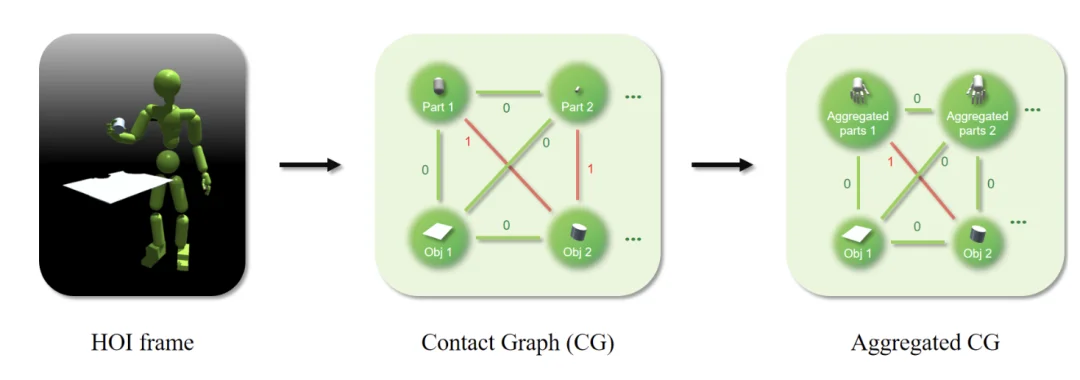
Ayrıca, kinematik taklit ödüllerinin optimal çözümde takılıp kalmasını önlemek için çalışmada temas grafiği de tanıtılmıştır .
Bir HOI çerçevesi verildiğinde, temas grafiği düğümleri tüm vücut parçalarını ve nesneleri içerir. Her kenar, temasın gerçekleşip gerçekleşmediğini gösteren ikili bir temas etiketidir. Hesaplamayı kolaylaştırmak için, birden fazla vücut parçası tek bir düğümde bir araya getirilerek toplu bir temas grafiği oluşturulabilir.
Ayrıca, HOI senaryosunun eksikliklerini telafi etmek için çalışmada tam vücut basketbol becerilerine ilişkin BallPlay veri seti de tanıtılmıştır.
Yapılan deneyde PhysHOI’nin farklı boyutlardaki basketbol toplarını tutmada sağlam olduğu görüldü.
Bir şey daha
Wang Yinhuai’nin PhysHOI, SkillMimic ve SkillMimic-v2 adlı üç makalede de önemli bir rol oynadığını ve internet kullanıcılarının ona şakayla “bir numaralı basketbol araştırmacısı” dediğini belirtmekte fayda var .
Wang Yinhuai, Hong Kong Bilim ve Teknoloji Üniversitesi’nde ikinci sınıf doktora öğrencisidir ve danışmanı Profesör Tan Ping’dir .
Daha önce Pekin Üniversitesi’nde yüksek lisans , Xi’an Elektronik Bilim ve Teknoloji Üniversitesi’nde lisans eğitimini tamamlamış , IDEA Research, Unitree Technology ve Şanghay Yapay Zeka Laboratuvarı gibi kurumlarda staj yapmıştır.
2023 yılında simülasyon ortamında yapılan ilk deneme çalışmasından, robotun gerçek bir ortamda top oynamasına kadar geçen sürede, robotun kendisinin geliştirilmesi sayesinde kaydedilen ilerleme gerçekten dikkat çekici!
Referans Bağlantıları
[1]https://x.com/NliGjvJbycSeD6t/status/1991536374097559785
[1]https://x.com/NliGjvJbycSeD6t/durum/1991536374097559785
[2]https://wyhuai.github.io/info/
[3]https://ingrid789.github.io/SkillMimicV2/
[4]https://wyhuai.github.io/physhoi-page/[5]https://ingrid789.github.io/SkillMimic/
[4]https://wyhuai.github.io/physhoi-page/ [5]https://ingrid789.github.io/SkillMimic/
Benzer Yazılar

OpenAI, GDPval değerlendirme yöntemini tanıttı; büyük modeller üç büyük sektörde insanları ikame edebiliyor. OpenAI,...
Google, yapay zeka destekli araçlarındaki gelişmelere bir yenisini ekleyerek Gemini platformuna NotebookLM entegrasyonu getirdi. Bu...
