





















Google Nano Banana Pro piyasaya çıktığı anda tüm internet haykırdı: Bu maketin içinde ne var yahu?!...
Büyük Modellerde Ajan Değişimi: Ajan Tabanlı Pekiştirme Öğreniminin Kapsamlı Bir Özeti
Yazı Özetini Göster

Son iki yılda, **Üretken Yapay Zeka (AI)** dalgası tüm dünyayı sardı. ChatGPT’den Claude’a, yerel GLM, Tongyi Qianwen, Wenxin gibi modellere kadar **Büyük Dil Modelleri (LLM)**, yapay zeka gelişiminin temel motoru haline geldi.
Bu modeller makaleler yazabilir, kod yazabilir, hikayeler oluşturabilir ve hatta bilimsel araştırmalara katılabilir. Ancak aynı zamanda, araştırmacılar temel bir sorun keşfetmeye başladı:
Bu modeller yüksek kaliteli dil üretebilse de, gerçek bir eylem yeteneğine sahip değiller. Planlama, araç kullanma veya ortamla etkileşim gerektiren görevlerle karşılaştıklarında genellikle yetersiz kalırlar.
Bir dil modelinin sadece “soru cevaplamaktan” çıkıp, “görevleri özerk bir şekilde yürütebilmesini” nasıl sağlayabiliriz? Bu, güncel yapay zeka araştırmalarındaki en zorlu sorulardan biridir.
Yakın zamanda, **Oxford, UCSD, NUS, ICL, UIUC, UCL, Şangay Yapay Zeka Laboratuvarı** gibi on altı önde gelen kurumdan akademisyenlerin ortaklaşa hazırladığı bir inceleme makalesi sistematik bir yanıt sundu.

Makale Bağlantısı: https://arxiv.org/abs/2509.02547
Açık Kaynak Proje: https://github.com/xhyumiracle/Awesome-AgenticLLM-RL-Papers
Yüz sayfayı aşan bu inceleme, 500’den fazla ilgili araştırmayı birleştirerek **Ajan (Agentic) Takviyeli Öğrenme (Reinforcement Learning – RL)** kavramını, çerçevesini ve uygulamalarını ilk kez sistematik bir şekilde ele alıyor.
Pasif Yanıttan Aktif Karar Vermeye: Agentic RL’nin Temel Fikri
Geleneksel Takviyeli Öğrenmede (RLHF, DPO vb.), dil modelleri “tek adımlı yanıt sistemleri” olarak tasarlanır. Girdiyi alır, çıktıyı üretir ve insan geri bildirimi veya tercihlerine göre parametreleri ayarlar. Bu paradigmanın temsilcisi ChatGPT’nin eğitim şeklidir.
Ancak, bu mekanizma yalnızca tek döngülü optimizasyon için uygundur ve uzun vadeli planlama ve ortamla etkileşim gerektiren görevleri ele alamaz.
**Agentic RL** ise yepyeni bir bakış açısı sunar. Bu çerçeve, büyük dil modelini dinamik bir ortama yerleştirilmiş bir **ajan (Agent)** olarak ele alır ve takviyeli öğrenme mekanizması aracılığıyla modele **sürekli algılama, ardışık karar verme, araç kullanma ve kendini optimize etme** yeteneği kazandırır.
Araştırmacılar bu süreci **Kısmen Gözlemlenebilir Markov Karar Süreci (POMDP)** olarak biçimlendirir: Model, ortam hakkında tam bilgiye sahip olmasa bile, mevcut bilgilere dayanarak karar verebilir, eylemler gerçekleştirebilir ve geri bildirim sinyalleriyle stratejisini sürekli güncelleyebilir.
Başka bir deyişle, **Agentic RL’nin amacı modelin “daha iyi cevaplar üretmesi” değil, “hedefe ulaşmak için nasıl hareket edeceğini öğrenmesi”**dir.
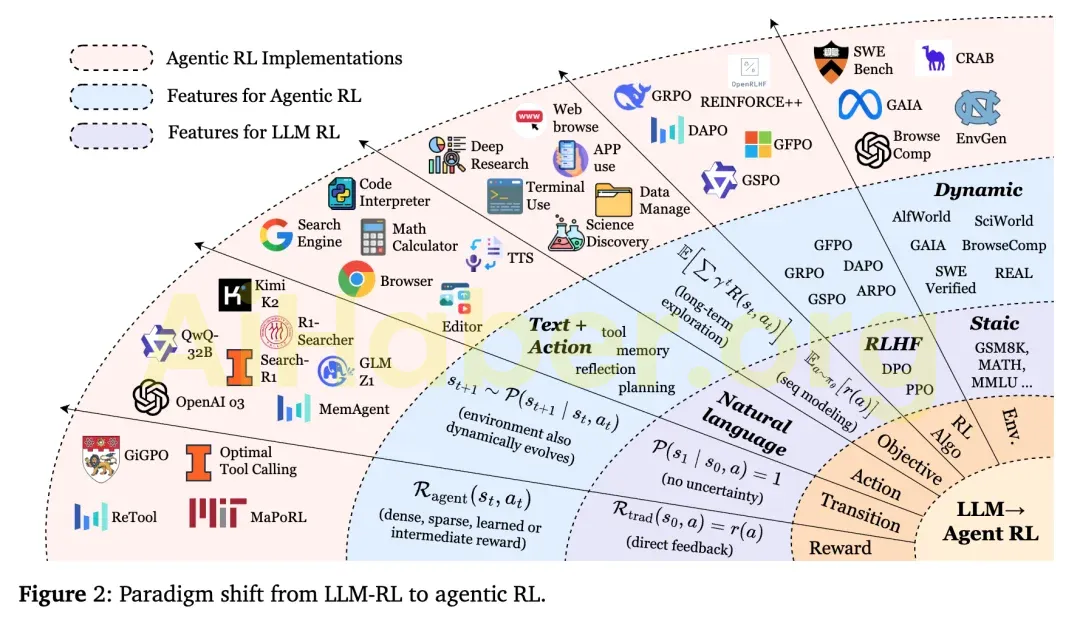
Altı Temel Yetenek: Dilden Zekaya Sıçrama
Makalede, gerçek bir ajanın sahip olması gereken altı temel yetenek olduğu belirtiliyor. Bunlar aynı zamanda Agentic RL’nin de yapı taşlarıdır.
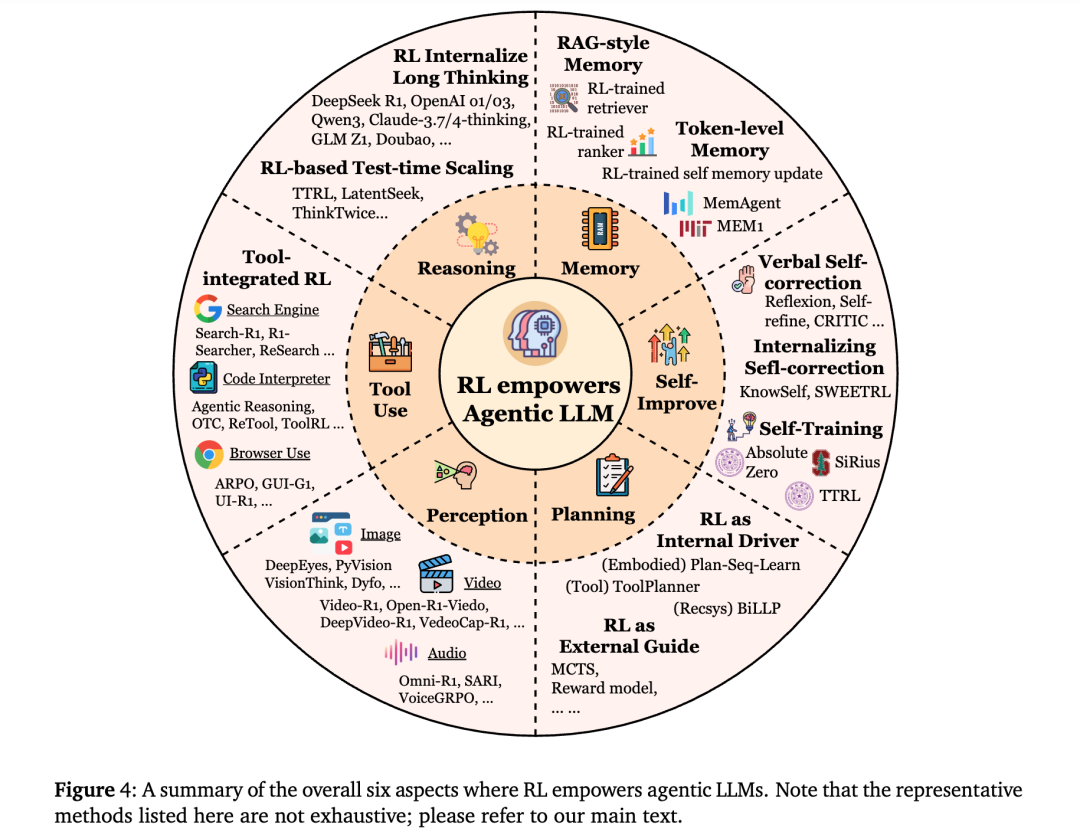
Planlama (Planning)
Model, karmaşık görevleri ayırabilir, çok adımlı eylem planları oluşturabilir ve geri bildirime göre yolu dinamik olarak ayarlayabilir. Örneğin, bir araştırma asistanı literatür tarama, veri analizi ve makale yazma adımlarını otomatik olarak planlayabilir.
Araç Kullanımı (Tool Use)
Geleneksel yöntemler harici araçları çağırmak için manuel komutlara dayanırken, RL sayesinde model ne zaman arama motoru, kod yürütücü veya veritabanı sorgulama arayüzü çağıracağına özerk bir şekilde karar verebilir.
Bellek (Memory)
Agentic RL, modelin uzun vadeli etkileşimlerde kritik bilgileri korumasını ve “neyi hatırlamaya değer olduğunu” öğrenmesini sağlar. Bu bellek mekanizması sadece açık metin belleğini değil, aynı zamanda örtük vektör temsillerini ve semantik erişimi de içerir.
Akıl Yürütme (Reasoning)
Model, görev gereksinimlerine göre “hızlı sezgisel akıl yürütme” ile “derin zincirleme akıl yürütme” arasında geçiş yapabilir. Takviyeli öğrenme, ödül sinyalleri aracılığıyla modelin daha istikrarlı ve mantıksal olarak tutarlı akıl yürütme yolları üretmesine rehberlik eder.
Kendini Geliştirme (Self-Improvement)
Ajan, deneyim biriktirme yoluyla yansıtma ve kendini düzeltme yapabilir, kapalı döngü öğrenme mekanizması oluşturur. Örneğin, hatalı çıktıları yansıtma eğitimi (Reflexion) ile modelin uzun vadeli performansı önemli ölçüde artar.
Algılama (Perception)
Dil modeli artık metin girdisiyle sınırlı kalmayıp, görüntü, ses, video gibi çok modlu bilgileri anlayabilir ve dış dünya ile bağlantı kurabilir.
Bu altı yeteneğin birleşimi, LLM’lerin “pasif dil üreticisinden” “aktif öğrenen ve hareket eden bilişsel sistemlere” geçişini mümkün kılar.
Yedi Temel Görev Türü: Agentic RL Uygulama Haritası
Teorik çerçevenin yanı sıra, makale Agentic RL’nin pratikteki yedi ana görev senaryosunu da özetliyor.
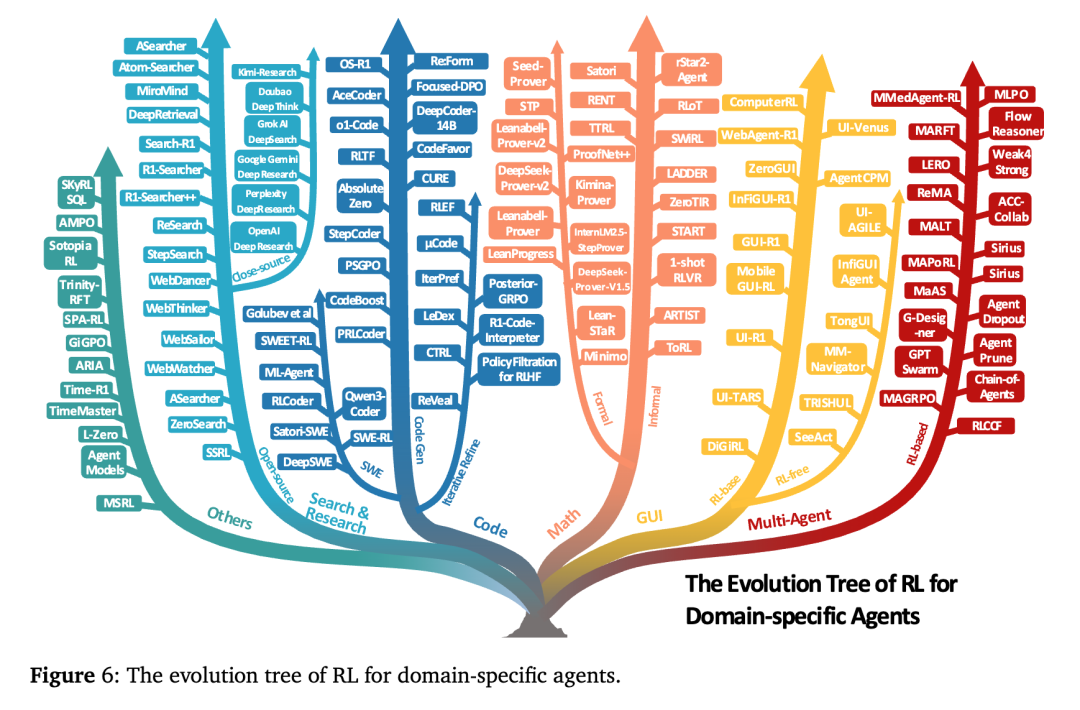
-
Bilgi Erişimi ve Araştırma Ajanları: Akademik veya haber araştırmaları için bilgiyi otomatik olarak alma, okuma ve birleştirme.
-
Kod Ajanları: Otomatik kod üretimi, hata ayıklama ve test etme (örneğin SWE-Bench, AgentCoder).
-
Matematik ve Mantıksal Akıl Yürütme: Karmaşık hesaplama, kanıtlama ve formül üretme problemlerini çözme.
-
GUI İşlem Ajanları: Grafik arayüzde eylemler gerçekleştirme, insan-bilgisayar etkileşimi görevlerini gerçekleştirme.
-
Görsel ve Çok Modlu Ajanlar: Görüntü algılamayı dil akıl yürütmesiyle birleştirerek çapraz modlu görevleri destekleme.
-
Somut Ajanlar (Embodied Agents): Sanal veya fiziksel ortamlarda çok adımlı görevleri tamamlama.
-
Çok Ajanlı Sistemler (Multi-Agent Systems): Otomatik araştırma veya toplu iş birliği görevleri gibi karmaşık hedefleri tamamlamak için birden fazla modelin iş birliği yapması.
Bu görevler net bir eğilimi gösteriyor: Agentic RL, dil modellerini “metin dünyasından” “eylem dünyasına” taşıyor ve yapay zekanın gerçek ortamlarla etkileşim kurma yeteneğini kazanmasını sağlıyor.
Ekosistem Oluşturma: Açık Ortamlar ve Temel Çerçeveler
Makale aynı zamanda Agentic RL araştırmalarının dayandığı **açık ortamları, değerlendirme kıyaslamalarını ve eğitim çerçevelerini** de sistematik olarak düzenlemiştir.
-
Ortamlar (Environments): AlfWorld, GAIA, BrowseComp, SWE-Bench gibi çok modlu ve çok görevli eğitimi destekleyen ortamlar.
-
Değerlendirme Kıyaslamaları (Benchmarks): Arama, akıl yürütme, araç kullanımı, etkileşimli işlemler gibi görev boyutlarını kapsayan kıyaslamalar.
-
RL Çerçeveleri (RL Frameworks): PPO, DPO, GRPO gibi çeşitli takviyeli öğrenme algoritmaları ve geliştirilmiş versiyonları.
Yazar ekibi ayrıca kapsamlı bir kaynak listesi olan **Awesome-AgenticLLM-RL-Papers’ı** açık kaynak olarak yayınladı. Bu liste, araştırmacılara teoriden deneye kadar sistematik bir referans sunarak makaleleri, ortamları, kıyaslamaları ve açık kaynak uygulamaları bir araya getiriyor.
Gelecekteki Zorluklar ve Araştırma Yönleri
Agentic RL büyük bir potansiyel göstermesine rağmen, hala bazı zorluklarla karşı karşıya.
-
Güvenilirlik (Trustworthiness): Ajanların karmaşık ortamlardaki davranışlarının güvenli, açıklanabilir ve kontrol edilebilir olması nasıl sağlanır?
-
Eğitim Ölçeklenebilirliği (Training Scalability): Uzun vadeli etkileşim görevleri genellikle büyük miktarda hesaplama kaynağı gerektirir; verimlilik ve performans arasında nasıl denge kurulur?
-
Ortam Ölçeklenebilirliği (Environment Scalability): Mevcut simülasyon ortamları hala sınırlıdır; gerçek dünyaya daha yakın etkileşim alanları nasıl inşa edilir?
Bunun yanı sıra, ajanların etik, güvenlik ve sosyal etkileri de önemli araştırma konuları haline geliyor. Agentic RL’nin gelişimi sadece bir algoritma yeniliği değil, aynı zamanda insanlığın akıllı sistemlerle nasıl bir arada yaşayacağını keşfetme sürecidir.
Ajan Çağına Doğru
Agentic RL, dil modeli araştırmalarında “üretimden” “eyleme” doğru önemli bir dönüm noktasını işaret ediyor. Modelin önceden ayarlanmış senaryolara bağımlı kalmayıp, ortamda özerk bir şekilde keşfetmesini, sürekli öğrenmesini ve geri bildirime göre sürekli optimize etmesini sağlıyor.
Araştırmacılar için bu çerçeve yeni bir teorik temel ve sistematik bir bakış açısı sunarken; geliştiriciler için karar verme ve işlem yapabilen yapay zeka sistemleri oluşturmanın anahtar yolu; tüm yapay zeka ekosistemi için ise “dil zekasından” “genel zekaya” doğru yeni bir aşama anlamına geliyor.
Geleceğin yapay zekası sadece sohbet etmekle veya yazmakla kalmayacak, aynı zamanda gözlemleyebilecek, düşünebilecek, uygulayabilecek ve yansıtabilecek. Agentic RL, bu gerçek anlamdaki “somut zeka”ya kapı açıyor.
İçerikte yer alan görseller telif hakkı içeriyorsa, lütfen silinmesi için bizimle iletişime geçin.
Benzer Yazılar

1.3 metre boyundaki Little Potato isimli robot, ipeksi bir pürüzsüzlükte katmanlama yapabiliyor. Yanlış anlamayın,...

Üretken yapay zeka, konseptten prototipe ve çözüme giden yolculuğu hızlandırarak kuruluşların sorunları çözme biçiminde devrim...