





















欢迎使用WordPress。这是您的第一篇文章。编辑或删除它,然后开始写作吧!
Yazı Özetini Göster

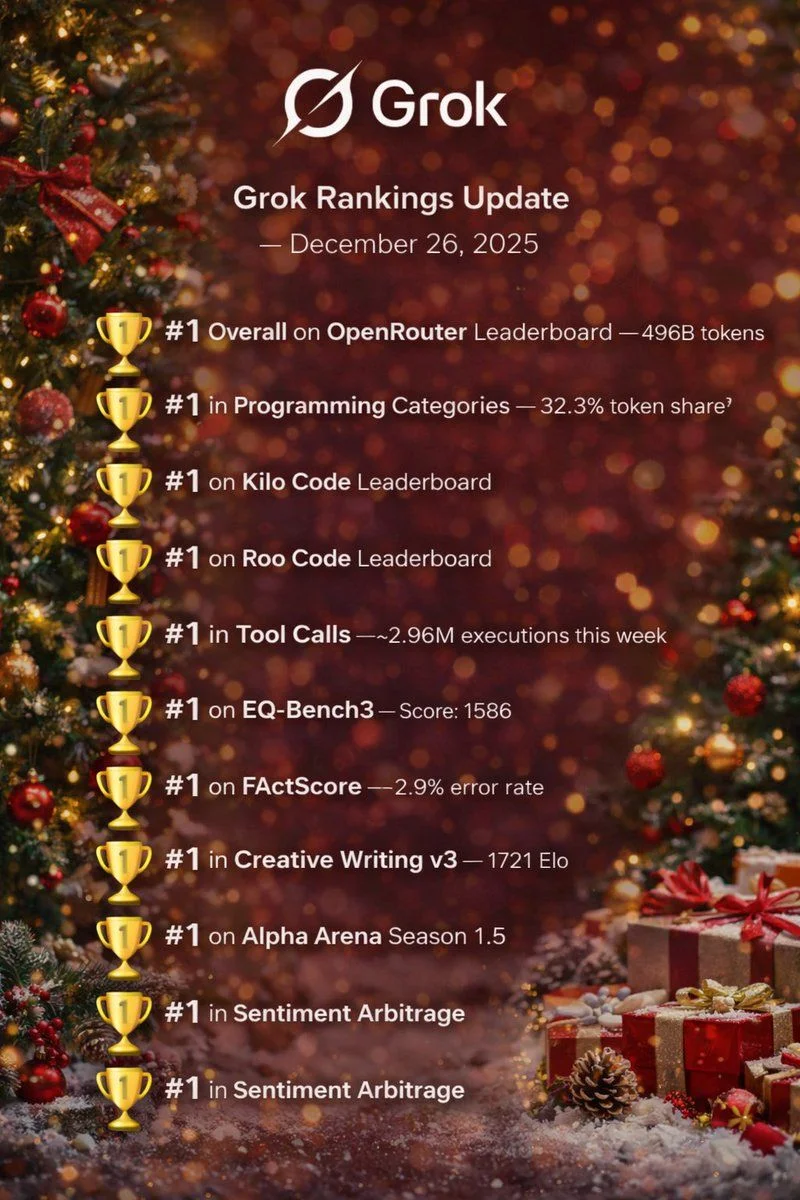
Yapay zeka teknolojileri her geçen gün daha karmaşık testlerden geçerken, OpenRouter’ın son verileri bu alandaki rekabetin geldiği noktayı açıkça gözler önüne sermektedir. Özellikle Grok isimli model, bir dizi kıyaslama testinde dikkat çekici bir başarıya imza atmıştır. Haftalık yaklaşık 517 milyar token işleme kapasitesiyle yalnızca hacim açısından değil, aynı zamanda doğruluk ve verimlilik bakımından da sektör liderliğini güçlendirmiştir. Bu rakam, modelin ölçeklenebilirliğini ve kullanıcı etkileşimi hacmini yansıtmakta, aynı zamanda sistemin pratikte ne kadar yaygın şekilde kullanıldığını da göstermektedir.
Programlama alanındaki başarısı, Grok’un teknik becerilerdeki derinliğini açıkça ortaya koymaktadır. Model, Kilo Code, BLACKBOXAI, Roo Code ve Cline gibi rekabetçi sistemlerle yapılan karşılaştırmalarda birinci sırayı elde etmiştir. Üstelik programlama kategorisindeki token kullanım oranı %32,7 gibi oldukça yüksek bir seviyeye ulaşarak, kodlama görevlerinde üstün bir performans sergilemiştir. Bu, Grok’un yalnızca kelime işleme değil, aynı zamanda kodun anlamını çözme, hataları ayıklama ve kompleks algoritmaları anlama gibi ileri teknik kabiliyetlerde de öne çıktığını göstermektedir.
Veri Odaklı Performans Değerlendirmesi
OpenRouter tarafından paylaşılan teknik değerlendirme raporları, Grok’un çok boyutlu sınavlar ve duygu analizi testlerindeki başarısını ayrıntılı biçimde ortaya koymaktadır. EQ-Bench3 isimli duygu anlama testinde 1586 puan elde ederek ortalamanın oldukça üzerinde bir sonuç kaydetmiştir. Bu skor, Grok’un metinler arasındaki bağlamı anlama, tonlama farklılıklarını yorumlama ve duygusal nüansları sezme alanlarındaki güçlü sezgisel kapasitesine işaret etmektedir.
Ek olarak, FActScore olgu doğruluğu testinde yalnızca %2,9 hata oranı ile oldukça düşük bir sapma göstermiştir. Bu sonuç, modelin ürettiği bilgilerin doğruluk düzeyinin yüksek olduğunu ve bilgi güvenilirliği açısından emsalleriyle kıyaslandığında daha istikrarlı sonuçlar ürettiğini göstermektedir. Yaratıcı yazarlık alanındaki Creative Writing v3 değerlendirmesinde aldığı 1721 Elo puanı, Grok’un dil estetiği, akıcılığı ve orijinal içerik üretme yeteneğinde de bir denge yakaladığını ortaya koymaktadır.
Uygulama Alanları ve Geleceğe Yönelik Potansiyel
Grok’un yüksek işlem kapasitesi ve testlerde elde ettiği başarı oranı, kurumsal ve bireysel kullanım senaryolarında geniş bir yelpaze sunmaktadır. Özellikle yazılım otomasyonu, veri analitiği, müşteri etkileşim sistemleri ve akademik araştırmalar gibi disiplinlerde Grok, insan benzeri akıl yürütme becerileriyle çözüm süreçlerini önemli ölçüde hızlandırabilir. Ayrıca, yaklaşık 2,96 milyon araç çağrısı gerçekleştirmesi, sistemin etkileşim oranının ne denli yüksek olduğunu ve farklı uygulama platformlarıyla entegrasyon yeteneğini göstermektedir.
Bütün bu bulgular, Grok’un yalnızca mevcut performans göstergelerinde değil, yapay zekâ ekosisteminin geleceğini şekillendirmede de belirleyici bir rol oynayabileceğini göstermektedir. Modellerin güvenilirlik, ölçeklenebilirlik ve bağlamsal anlama gibi temeller üzerinde yükseldiği bu yeni dönemde, Grok’un geliştirilmiş algoritma mimarisi ve bilgi işleme yetisi, onu geleceğin dijital zekâ altyapısında kritik bir aktör konumuna taşımaktadır.
Benzer Yazılar

1、研究报告称,日本福岛26.7万多张野生动物照片记录了20余种动物,包括:野猪、日本野兔、猕猴、野鸡、狐狸、浣熊等。 新浪科技讯 北京时间1月8日消息,据国外媒体报道,美国佐治亚大学最新研究称,日本福岛核泄漏事件带来一场灾难,该地区一片荒芜,没有人类生活的迹象,但是现今10年过去了,这里变成了野生动物的天堂,存在着大量种类繁多的野生动物。 一份基于相机记录的研究报告发表在《生态与环境前沿期刊》上,该研究报告称,日本福岛26.7万多张野生动物照片记录了20余种动物,包括:野猪、日本野兔、猕猴、野鸡、狐狸、狸(狐狸的近亲物种)等。 佐治亚大学野生动物生物学家詹姆斯·比斯利(James Beasley)说:“切尔诺贝利和福岛核事故发生数年之后,科学界和公众非常关注该区域野生动物的生存状况,希望了解核辐射对野生动物构成怎样的影响。” 2、图中是一只正在觅食的狸。 之前一些研究报告揭晓了切尔诺贝利核电站野生动物生存状况,近期科学家也开始关注核泄漏事件发生10年之后的日本福岛。 比斯利表示,我们的研究结果首次证实,尽管福岛存在着辐射污染,但在疏散区,仍有大量野生动物生存,并且种类达到20多种。相机拍摄到人类疏散区存在与人类发生冲突的物种,尤其是野猪,这表明当人类撤离之后,这些物种数量大幅增加。 福岛大学环境放射性研究所教授托马斯·辛顿(Thomas Hinton)等人在福岛发现具有生物多样性的3个区域,相关摄影数据来自3个区域的106个拍摄点,这3个区域是:高辐射污染的无人区;中等辐射污染的人类活动限制区;较低环境辐射污染的人类可居住区。 在相机观察的120天里,相机拍摄了4.6万张野猪照片,其中2.6万张是在无人区拍摄的,1.3万张是在人类活动限制区拍摄的,0.7万张是在人类可居住区拍摄的。 3、日本鬣羚是一个例外,它是一种类似山羊的哺乳动物,平时会远离人类,但在福岛有人居住的高地区域频繁发现它们的活动踪迹,研究人员称,这可能是一种动物行为调整,鬣羚会避开疏散区数量较多的野猪。 在无人区和人类活动限制区拍摄次数较多的其他物种包括:浣熊、日本貂和日本猕猴。辛顿指出,最新研究报告并不是对动物健康的评估分析,仅是对该区域野生动物种群的观察记录。这项研究具有重要作用,其调查了核辐射对野生动物种群的影响,而此前大多数研究都是观察分析对单个动物的辐射危害,在此次研究中无人区作为研究控制区,尽可能减少人类进入次数。 科学家称,虽然之前没有关于疏散区野生动物数量的统计,但其与人类可居住区的地理位置和地形相似,因此该区域是最佳观察地点。...

Dükkan sahibi Claude: Yapay zeka bir işletmeyi yönettiğinde ne olur? Anthropic'in San Francisco ofisinin sakin...