




















University College London ve Huawei'nin Nuh'un Gemisi Laboratuvarı tarafından ortaklaşa geliştirilen Memento sistemi, LLM ajanları...
Yazı Özetini Göster







Araştırma geçmişi
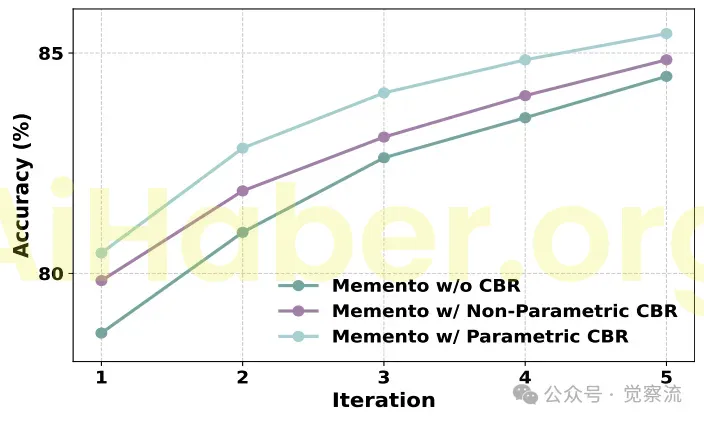
temel yenilik
tasarım detayları

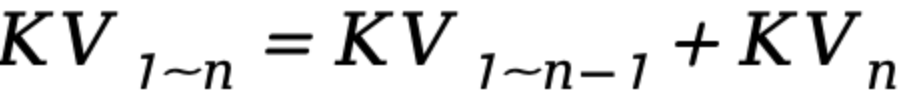


genel performans

LongSANA:Gerçek zamanlı olarak uzun video oluşturma

Terminal cihazı dağıtımı
Referanslar:
https://arxiv.org/pdf/2509.24695
Saniyede 27 kare hızında gerçek zamanlı video üretimi ve 35 saniyede 1 dakikalık yüksek tanımlı video sentezi; bu uzak bir gelecek değil, NVIDIA’nın MIT ve Hong Kong Üniversitesi’nden oluşan ekibi tarafından yakın zamanda ortaya çıkarılan bir gerçeklik.
Yeni nesil video dağıtım modeliSANA-VideoHiçbir yerden doğdu. Devrim niteliğindeki doğrusal DiT mimarisi ve sabit bellekli KV önbellek mekanizmasıyla, yalnızca hız açısından tüm benzer modelleri aşmakla kalmıyor, aynı zamanda 720p’ye kadar çözünürlükler ve dakika düzeyinde süre üreterek AI video oluşturmanın verimlilik sınırını yeniden tanımlıyor.
SANA-Video yalnızca hız ve performans açısından mükemmel olmakla kalmıyor, ürettiği görüntü kalitesi de çok yüksek.
SANA-Video tarafından oluşturulan bazı örnekler:

Temel avantajları şunlardır:
· Yüksek verimlilik:kullanmakDoğrusal DiT ve video belleği sabit KV önbelleğiGeleneksel modellere göre daha yüksek hızlara ve daha yüksek bellek verimliliğine ulaşıyor.
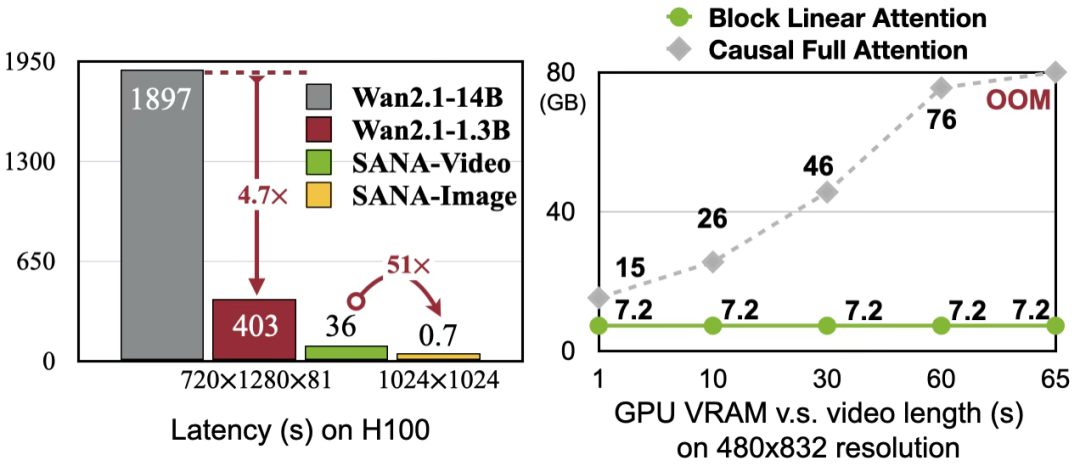
· düşük maliyet: Eğitim maliyeti son derece düşüktür (MovieGen’in yalnızca %1’i) ve çıkarım hızı SOTA modelinden 16 kat daha hızlıdır.
· Konuşlandırılabilirlik: RTX5090’a kurulabilir ve yalnızca 29 saniyede 5 saniyelik 720p video oluşturabilir.
· Uzun videoların gerçek zamanlı oluşturulması: 4 adımlı damıtma versiyonunun uzun video oluşturma çeşidi (LongSANA), 1 dakikalık 480p video oluşturmak yalnızca 35 saniye sürer. Hız ve kalite arasında,SANA-VideoYeni bir kriter belirlendi.
Bu makale SANA-Video’nun yenilikçi teknolojisine ve üstün performansına derinlemesine bakacaktır.
Makale başlığı:SANA-Video: Verimli Video ÜretimiEngellemekDoğrusal Difüzyon Transformatörü
Kağıt adresi:https://arxiv.org/pdf/2509.24695
Proje ana sayfası:https://nvlabs.github.io/Sana/Video/
Metinden görüntüye ve video üretimi alanında, difüzyon modeli (Diffusion Transformer) dikkate değer bir başarı elde etti.
Difüzyon modeli birden fazla tokenı paralel olarak işleyebilmesine rağmenYüksek çözünürlüklü görüntü ve video oluşturmaŞu anda, çok sayıda jeton, çıkarım hızının yavaşlamasına neden oluyor.
Bu sorun, 5 saniyelik 81 karelik videonun eş zamanlı oluşturulmasının görüntü oluşturmaya göre 50 kat daha hızlı olduğu metinden videoya alanında daha da belirgindir.
Hesaplama verimliliğini artırmak için,Çok sayıda token içeren video görevleri gibi görevlerde,doğrusal dikkatHesaplama karmaşıklığında önemli tasarruflar.
Şu anda Linear Attention ve Softmax Attention’ı birleştiren bazı yöntemler iyi sonuçlar elde etmiştir, ancakSıfırdan eğitilmiş Küresel Doğrusal Dikkat modeliyetenekleri konusunda hala belirsizlikler var.
Doğrusal DiT modelinde SANA-VideoSANA-Image’ın TemelleriBu konuda eğitime devam edin ve onun küresel doğrusal dikkatin model tasarımını miras alın.Etkin eğitimin tüm sürecini ve görüntü ve video modellerinin sıfırdan çıkarımını gerçekleştirirfizibilite bu sefer önerilen hem 8x sıkıştırmalı Wan-VAE hem de 32x sıkıştırmalı DC-AE-V üzerinde doğrulandı.
Nihai etki darbeye karşı dayanıklıdır ve Vbench’teki Wan-2.1 gibi açık kaynaklı difüzyon video modelleriyle aynıdır.
SANA-Video’nun özü yenilikçiliğinde ve Lupin’inKüresel Doğrusal Dikkat Difüzyon Transformatörüeğitim çerçevesi ve benzersizKüresel video belleği sabiti KV önbellek mekanizması.
Başlıca katkılar şunları içerir:
-
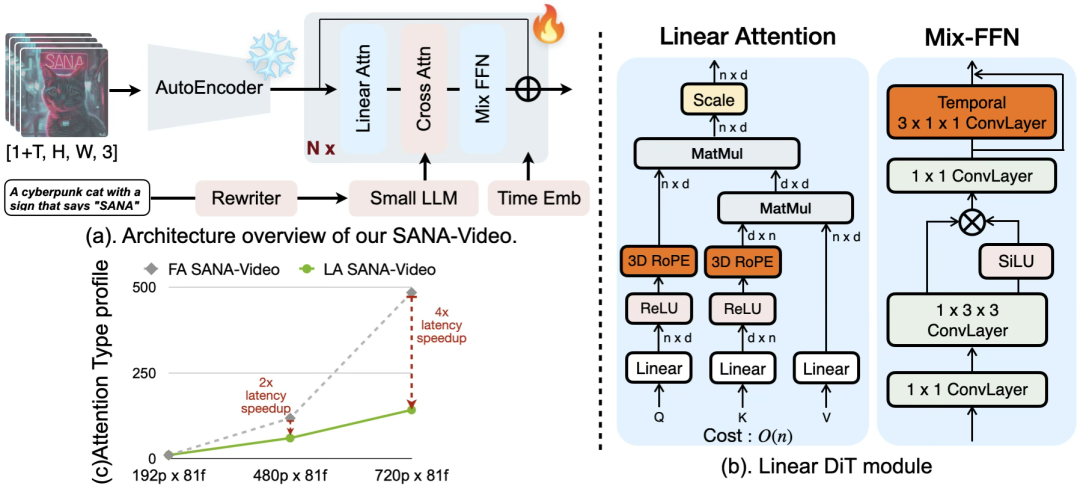
Doğrusal dikkat DiT(Doğrusal DiT):Video üretiminde büyük miktarda jeton işlemenin hesaplamalı darboğazını hedefleyen model, temel işlemi olarak doğrusal dikkati kullanıyor. Geleneksel öz-dikkat mekanizmalarıyla karşılaştırıldığında doğrusal dikkat, uzun dizileri işlerken daha verimlidir; bu, yüksek çözünürlüklü uzun videoları sentezlerken modelin mükemmel hız ve verimliliği korumasının temelini oluşturur.
-
Sabit Bellekli KV önbelleğe alma mekanizması (Sabit Bellekli KVÖnbellek):Dakikalarca süren videoları uygun maliyetli bir şekilde oluşturmak için araştırmacılar bir blok otoregresif yöntemi geliştirdi. Bu yöntem, sabit video belleğini kaplayan bir durum (KV önbellek) oluşturmak için doğrusal dikkatin kümülatif özelliklerinden yararlanır, böylece videonun uzunluğu arttıkça daha fazla video belleği tüketmeden modele genel bağlam bilgisi sağlanır. Bu tasarım, geleneksel KV önbelleğindeki bellek darboğazı sorununu tamamen çözer. Ve adımlı damıtma yoluyla,LongSANADakika düzeyindeki uzun videolar, gerçek zamanlı olarak otoregresif bir şekilde oluşturulabilir.
-
Derin sıkıştırmalı otomatik kodlayıcı (DC-AE-V):Geleneksel otomatik kodlayıcılar video alanını yalnızca 8 kez sıkıştırabilirken, yeni AE video alanını 32 kez sıkıştırarak potansiyel belirteçlerin sayısını etkili bir şekilde azaltır ve yüksek çözünürlüklü video üretimi için yeni bir hızın kilidini açar.
-
Mükemmel performans ve dağıtım verimliliği:SANA-Video, son derece yüksek verimlilik avantajları sergilerken, endüstrinin gelişmiş küçük dağıtım modelleriyle (Wan 2.1-1.3B gibi) karşılaştırılabilecek video kalitesine ulaşır.
Düşük eğitim maliyeti:Eğitim masrafı MovieGen’in yalnızca %1’idir.
Muhakeme hızı hızlıdır: Ölçülen gecikme benzer modellere göre 16 kat daha hızlıdır.
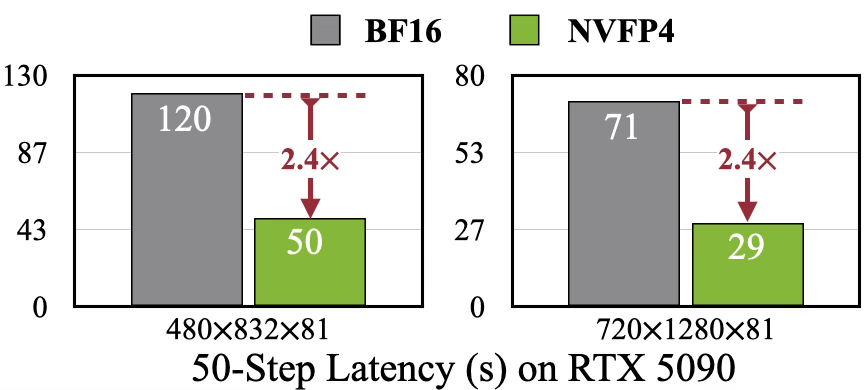
Tüketici düzeyinde dağıtım: RTX5090 GPU’ya başarılı bir şekilde dağıtılabilir ve NVFP4 hassasiyetini kullanarak 5 saniyelik 720p videonun üretim süresini 71 saniyeden 29 saniyeye kısaltarak gerçekten düşük maliyetli, yüksek kaliteli video üretimi gerçekleştirir.
Model mimarisinin detayları aşağıdaki tabloda gösterilmektedir.
· Verimli doğrusal DiT (Difüzyon Transformatörü)
Orijinal DiT’nin öz-dikkatli hesaplama karmaşıklığı, yüksek çözünürlüklü görüntüleri işlerken ikinci dereceden artan O(N²)’dir. Doğrusal DiT, burada geleneksel ikinci dereceden dikkat mekanizmasının yerini alarak hesaplama karmaşıklığını O(N²)’den O(N)’ye azaltır.
modeliSANA-Image eğitime devam ediyormodel ağırlıklarının çoğunu devralır, küresel doğrusal DiT mimarisini kullanmaya devam eder ve son olarak sıfırdan eğitilmiş eksiksiz bir Vincent görüntü ve video modelleri seti oluşturur.
Araştırmacılar aynı zamanda, tokenin yerel bilgisini geliştirmek için çok katmanlı algılayıcıda (MLP) 1×3×3 uzamsal evrişimi ve 3×1×1 zamansal evrişimi dönüşümlü olarak kullanabilen Uzamsal-Zamansal Karışım-FFN’yi de önerdiler.
Deneysel sonuçlar, doğrusal dikkatin geleneksel dikkatle karşılaştırılabilir sonuçlara ulaştığını ve 5 saniyelik video oluşturmadaki gecikmeyi kısalttığını göstermektedir.2-4 kez.
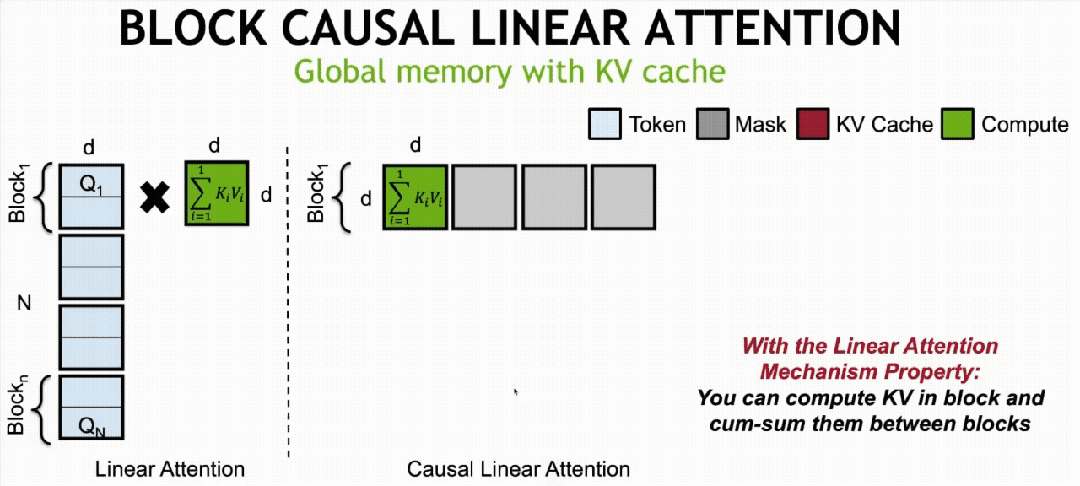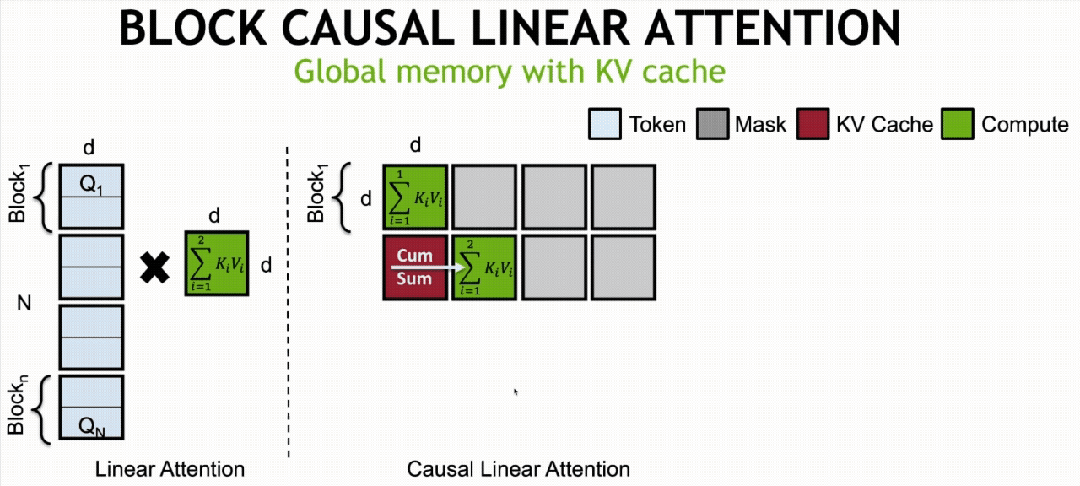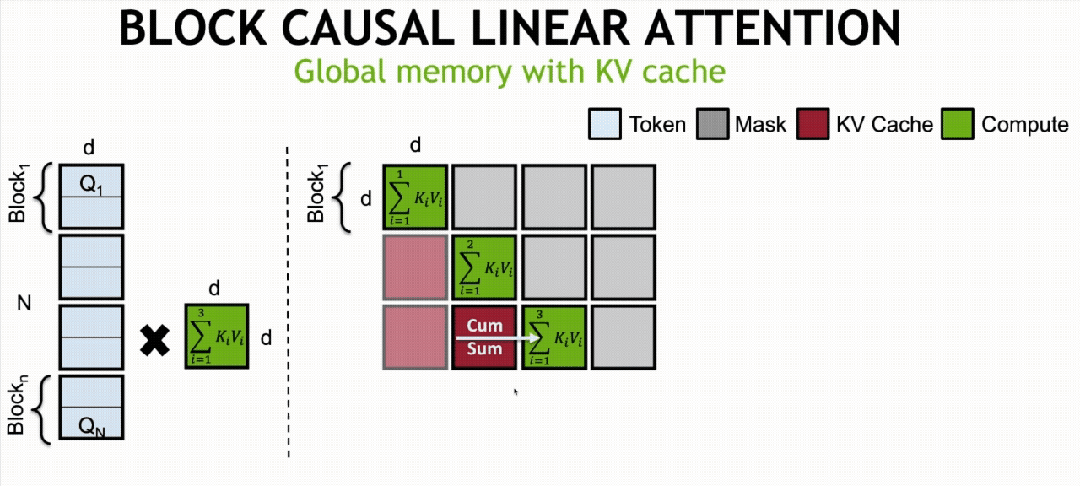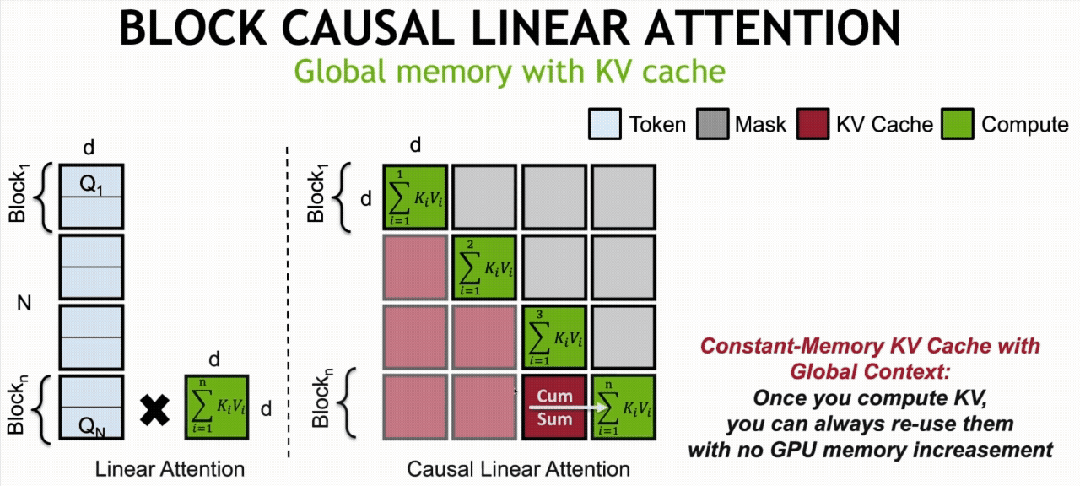
·Sabit Bellekli KV önbelleğe alma mekanizması (Sabit Bellekli KVÖnbellek)
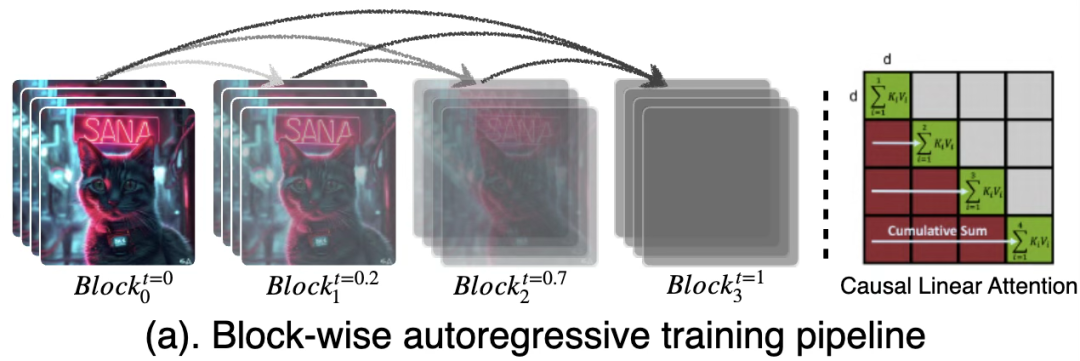
Doğrusal DiT’yi temel alarak bloklar arası otoregresif eğitim yöntemiyle uygulanır.doğrusal difüzyonu bloke etModel, küresel dikkatin özelliklerine sahiptir ancak sabit hafıza yüküne sahiptir.
Özellikle bloklar arası otoregresif eğitim yöntemi, bir videoyu N bloğa (Blok/Chunk) böler ve çerçevenin bulunduğu bloğun sırasına göre artan gürültü seviyeleri ekleyerek ve nedensel dikkat yoluyla modelleme yaparak difüzyon modeli eğitimi gerçekleştirir. Sonraki bloklar önceki blokların özelliklerini doğrusal dikkat yoluyla birleştirebilir, ancak önceki blokların özellik hesaplaması sonraki blokların özelliklerini ortaya çıkaramaz.
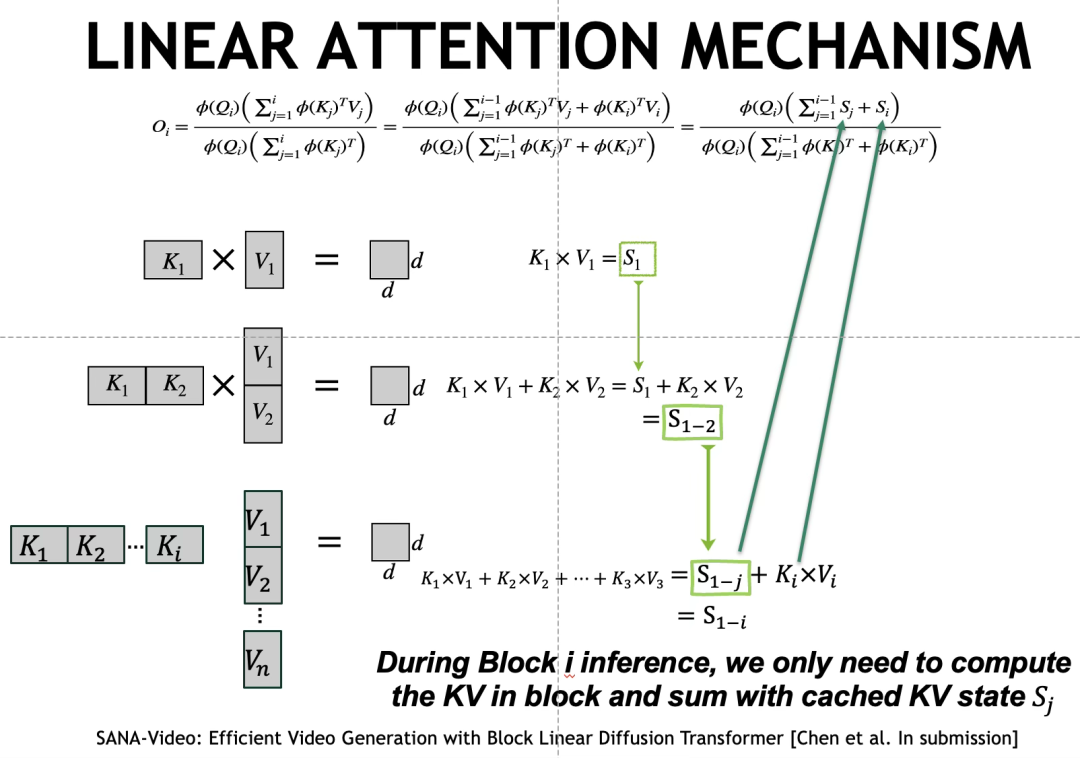
İlk olarak, doğrusal dikkat için, hesaplama mekanizması Token sırasına göre bölünebilir (matematiksel olarak eşdeğer) ve tüm Tokenların dikkat matrisi hesaplama sonuçları, KV çarpımı ve birikimi yoluyla elde edilebilir.
Bu nedenle ne zamanBlok Nedensel Doğrusal Yayılma Modeli (Nedensel DoğrusalDikkat)Eğitim tamamlandıktan sonra doğrusal KV önbellek mekanizması aracılığıyla uzun video çıkarım görevlerini gerçekleştirebiliyoruz.
Önbelleğe alma, blok 1’in KV1 hesaplaması tamamlandıktan sonra gerçekleştirilir. Blok 2’nin KV2 matrisi hesaplaması tamamlandığında KV1-2’yi elde etmek için KV1 matrisine eklenir. Benzer şekilde, son blok n’nin KVn hesaplaması tamamlandığında, yalnızca
Küresel KV matrisini alın. Buna dayanarak, her bloğun hesaplama miktarı yalnızca birikim matrisi KVsum’un ve mevcut bloğun hesaplanan KV’sinin toplamını içerir.
·Derin sıkıştırmalı otomatik kodlayıcı (DC-AE-V)
SANA modelinin tutarlı stratejisine uygun olarak araştırmacılar, ölçeklendirme faktörünü uzayda 32 kata ve zamanlamada 4 kata kadar büyük ölçüde artıran yeni bir video otomatik kodlayıcı (DC-AE-V) tanıttı.
F8T4C16+DiT kodlama katmanının 2 kat sıkıştırılmasıyla karşılaştırıldığında, F32T4C32’nin çıkardığı potansiyel belirteçlerin sayısı 4 kat azalır; bu, verimli eğitim ve yüksek çözünürlüklü videoların (720p çözünürlük gibi) oluşturulması için çok önemlidir.
· Etkin eğitim ve çıkarım stratejileri
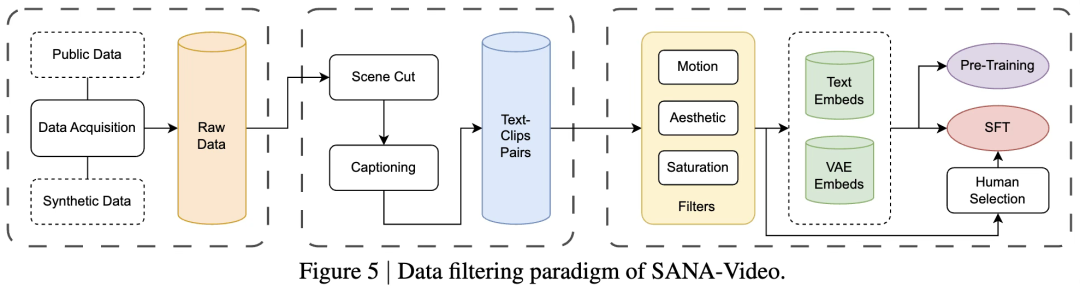
Eğitim maliyetlerini azaltmak için araştırmacılar hem verileri hem de eğitim stratejilerini optimize etti.
İlk olarak, veri düzeyinde etkili filtreleme standartları tasarladılar ve zengin ayrıntılar (konular, eylemler, ortamlar, kamera açıları vb.) içeren videolar için yüksek kaliteli metin açıklamaları oluşturmak amacıyla güçlü bir görsel dil modeli (VLM) kullandılar.
İkinci olarak, eğitim düzeyinde model, güçlü bir metinden resme (T2I) modeline dayalı olarak sürekli olarak önceden eğitilir ve düşük çözünürlükten yüksek çözünürlüğe kadar çok aşamalı bir strateji benimser.
Son olarak, videonun dinamik ve estetik özelliklerini verimli bir şekilde öğrenmek için insan tercih verileri kullanılarak denetimli ince ayar (SFT) gerçekleştirilir.
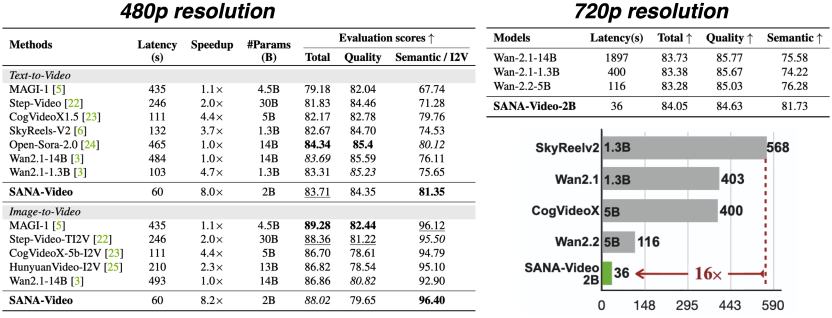
Aşağıdaki tabloda gösterildiği gibi SANA-Video, metin oluşturmaya yönelik mevcut en gelişmiş video dağıtım modeliyle karşılaştırılmıştır.
480p çözünürlüklü Metinden Videoya görevinde SANA-Video, yalnızca 2B model parametreleriyle en yüksek anlamsal hizalama puanına (Semantik Puan 81,35) ulaştı. Çıkarım gecikmesi yalnızca 60 saniyeydi ve bu diğer modellere göre daha hızlıydı.8 kezhız artışı.
480p çözünürlükteki Görüntüden Videoya görevinde SANA-Video aynı zamanda en hızlısıdır ve video oluşturma kalite puanı (I2V Puanı 96,40) tüm benzer modelleri geride bırakmaktadır.
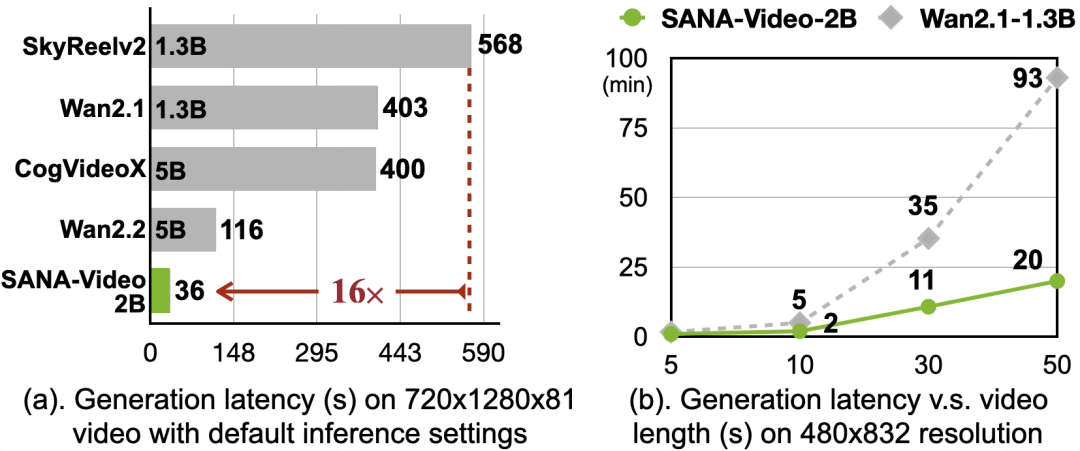
Daha yüksek çözünürlükteki (720p) performans karşılaştırmasında SANA-Video-2B, 84,05 Toplam Puanla en iyi performansı gösterdi.Çıkarım gecikmesi yalnızca 36 saniyedir; bu, SkyReelV2 (568 saniye) ve Wan2.1 (403 saniye) gibi modellerden daha yüksektir.16 kata kadar hız avantajı.
Aşağıda SANA-Video ve diğer modellerin görselleştirme performansının karşılaştırması yer almaktadır. Açıkçası SANA-Video model üretimi daha hızlı ve kalitesi de yüksek.
SANA-Video’nun sabit video belleği KV önbelleğe alma mekanizması, eğitim ve çıkarım için küresel dikkatin kullanımını destekler.
Bu nedenle araştırmacılar, Self-Forcing’in 5 saniyelik video otoregresif eğitim yöntemini geliştirdiler ve daha yüksek kalitede uzun videolar elde etmek için 1 dakikalık akış eğitimi için küresel ilgiyi kullandılar. Bu varyantın adıLongSANA. Gürültü giderme adımlarının sayısı ayrıştırıldığında H100’de 1 dakikalık bir video oluşturmak yalnızca 35 saniye sürer. Oluşturulan etki aşağıdaki gibidir:

Uç dağıtımını geliştirmek amacıyla araştırmacılar, modeli ölçmek için NVFP4’e yönelik SVDQuant algoritmasını kullandılar. Hem 480p hem de 720p video hızlarında 2,4 kat hızlanma elde edin. Ve RTX 5090 grafik kartlarında çıkarım yapılabilmektedir.
Geleceğe baktığımızda SANA-Video, gerçek zamanlı etkileşimli üretim gibi öncü alanları keşfetmeye kararlı olacaktır.
Araştırmacılar açıklığın gücüne kesinlikle inanıyorlar, bu nedenle tüm eğitim kodunu ve model ağırlıklarını topluluğa açık kaynak olarak sunmaya karar verdiler ve dünya çapındaki geliştiriciler ve araştırmacılarla video oluşturmanın sonsuz olanaklarını keşfetmeyi dört gözle bekliyorlar.
İçerikte yer alan resimler telif hakkı sorunları içeriyorsa lütfen bunları silmek için zamanında bizimle iletişime geçin.
Benzer Yazılar
Claude Code, yapay zekâ destekli programlama asistanları arasında farklı bir yere sahip. Onu özel kılan...

Araştırmacılar, proteinlerin dizilim, yapı ve işlev üçlü modunu aynı anda entegre eden ProTrek adında bir...