Bir IMO iç kaynağına göre, OpenAI aslında organizasyonla iş birliği yapmadı; AI altın madalyası iddiası gerçek olmayabilir.
En kritik nokta, onların IMO’nun “sonuç açıklama zamanı” kuralını çiğnemiş olması.
AI şirketlerinin insan öğrencilerin önüne geçmesini engellemek için IMO jüri üyeleri, sonuçların kapanış töreninden bir hafta sonra açıklanmasını şart koşuyor.
Oysa OpenAI, kapanış partisi henüz bitmeden sonuçları duyurdu.
Buna karşılık, Google DeepMind’dan Thang Luong, “Evet, IMO yönetiminin dışarıya duyurulmayan resmi bir puanlama standardı var” dedi.
O standarda uyulmadan yapılan herhangi bir madalya açıklaması geçersiz sayılır.
Eğer OpenAI’in puanından 1 puan düşersek, altın değil gümüş madalya alması gerekiyor.
Yani OpenAI’in “IMO altın madalyası” iddiası yalnızca kendini avutma olabilir!
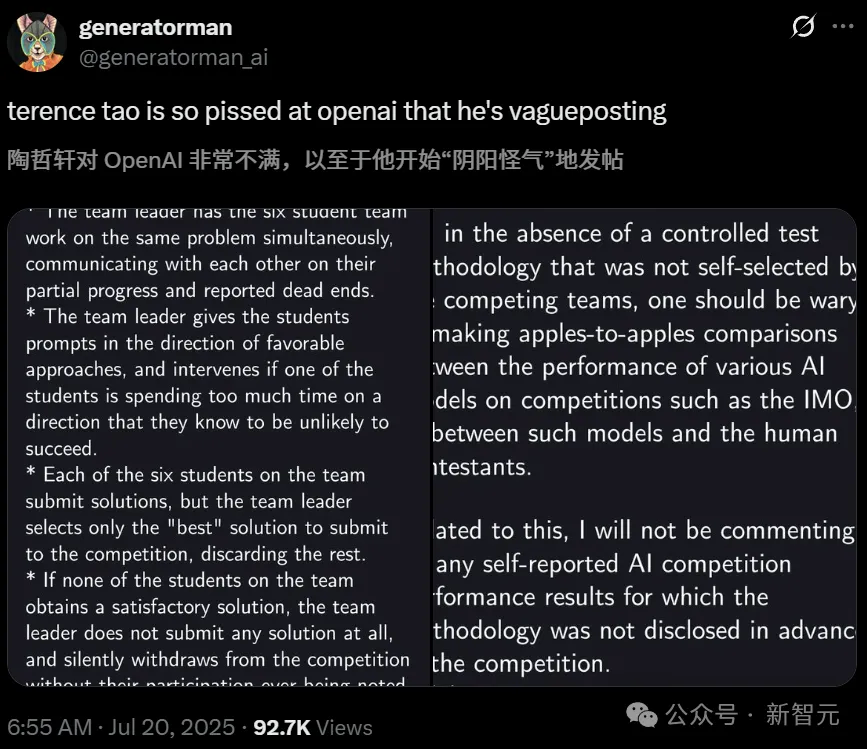
Dün, Fields Madalyası sahibi Terence Tao peşi sıra üç yorum paylaşarak açıkça OpenAI’i hedef aldı.
Tao, “Önceden açıklanmamış hiçbir test yöntemine dayanmayan AI yarışması sonuçlarına yorum yapmam” dedi. Kontrolsüz bir test ortamında AI’ın matematik yeteneğini doğru değerlendirmek zor, diye ekledi.
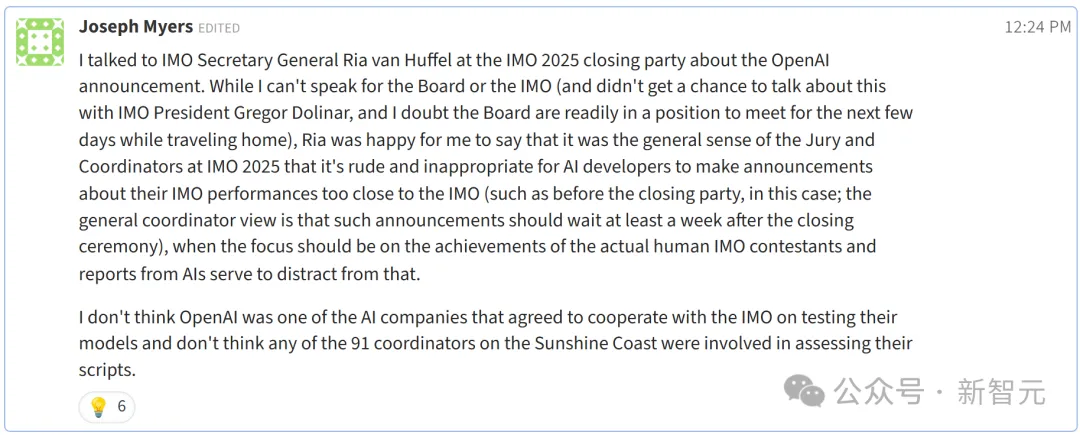
Ayrıca, IMO organizasyonundan Joseph Myers, OpenAI’in test edilen modelleri resmi olarak iş birliği içinde bulunan şirketler arasında olmadığını açıkladı. Sunshine Coast’taki 91 koordinatörden hiçbiri sonuç değerlendirme sürecine dahil edilmedi.
P6 sorusundan sorumlu koordinatör, “IMO jüri üyeleri ve koordinatörler, OpenAI’in bu hareketinin saygısız ve uygunsuz olduğunda hemfikir” açıklamasını yaptı.
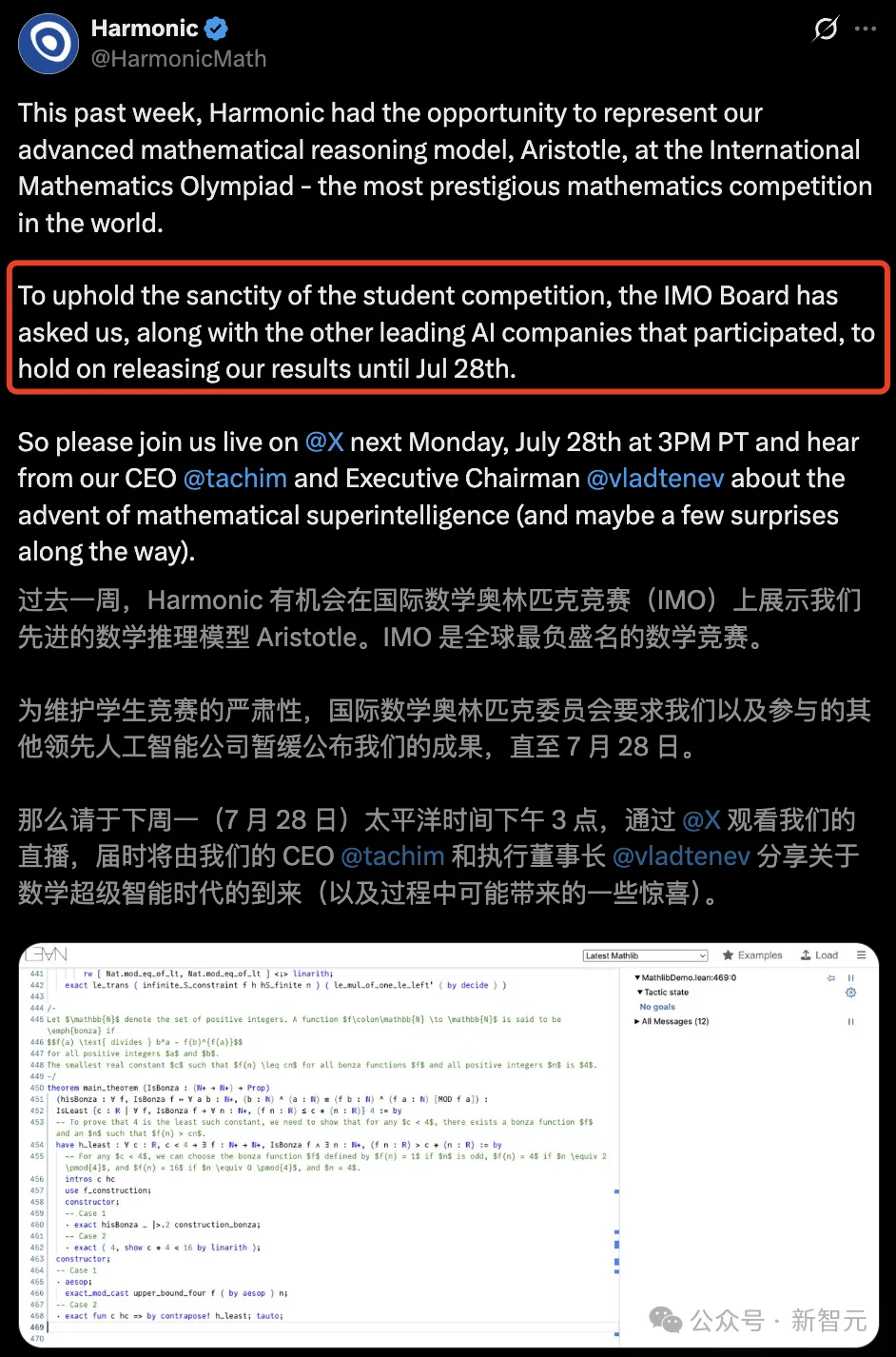
IMO kurallarına göre, AI modellerinin katılım sonuçları 28 Temmuz’dan sonra açıklanmalı.
Matematik odaklı bir AI girişimi olan Harmonic’in resmi paylaşımı da bu kuralın varlığını dolaylı olarak doğruladı.
Son Gelişmeler Tartışma Yarattı
OpenAI araştırma bilimcisi ve poker dünyasının efsane ismi Noam Brown iki nokta öne sürerek yanıt verdi:
Ekip, sonuçları kapanış töreninden “sonra” ilan etti. Kapanış töreninin canlı yayını kaydı var; bu kolayca teyit edilebilir.
OpenAI’in IMO’yla resmi bir koordinasyonu olmadığını ama duyurudan önce bir organizatöre haber verdiklerini onayladı. Yarışmacı öğrencilere saygı gösterisi olarak, kapanış töreni bitene kadar paylaşım yapmamaları istenmiş—“Biz de öyle yaptık.”
Bazı izleyiciler, kapanış töreni ve duyuru arasındaki zaman farkını detaylıca hesapladı:
IMO kapanış töreni 19 Temmuz’da (yerel saat) 16:00’da başladı, 1 saat 43 dakika sürdü; en geç 17:43’te bitti.
OpenAI kararının duyuru zamanı ise Doğu Zaman Dilimi’nde 19 Temmuz 15:50 olarak görünüyor ki bu yerel saate göre 17:50’ye denk geliyor.
Yani zamanlama itibarıyla OpenAI, kapanış töreni bitiminden 7 dakika sonra ilan yapmış oldu.
Buna rağmen birçok kişi, OpenAI’in bu PR atağını ve öğrencileri gölgede bırakma tutumunu doğru bulmadı.
Ve kesin olarak belirtmek gerekirse, OpenAI’in yayımladığı sonuçlar IMO tarafından resmi olarak onaylanmadı. Önümüzdeki günlerde Google DeepMind, AI’ın IMO 2025 başarı detaylarını resmen paylaşacak.
Kullanıcı Tepkileri ve Uzman Görüşleri
– Bir kullanıcı, “Bu tam da markanın tarzına uygun bir hamle,” diye tepki gösterdi. – UCLA Uygulamalı Matematik profesörü Ernest Ryu ise LLM’lerin kısa vadede insan matematikçileri ikame etmeyeceğini belirtti.
Ryu’ya göre:
OpenAI’in P1–P5 çözümleri muhtemelen doğrudur.
soru, yüksek orijinalite ve yaratıcılık gerektiren gerçek bir IMO zorluğu; P1–P5 hala standart tekniklerle çözülüyor ama P6 yaratıcı düşünce istiyor.
Ryu, kendi deneyimine dayanarak Gemini’nin ChatGPT’den daha iyi performans gösterdiğini söyledi.
Ancak OpenAI’in cumartesi günü erken duyuru yapması, Google DeepMind’in “yavaş bilim” akademik tavrının onları kamuoyu önünde dezavantajlı duruma düşürdüğünü gösterdi.
Ryu’ya göre, kısa vadede büyük dil modelleri matematikçilerin yerini alamayacak. Çünkü matematik araştırması, halen “hiç kimsenin nasıl çözeceğini bilmediği” sorunları (veri dağılımının dışında kalan, P6 gibi sorular) çözmeyi gerektiriyor; bu da büyük ölçüde yaratıcılık demek.
Ancak insanlığın zaten çözebildiği sorunlar (veri dağılımı içinde kalan) için LLM’ler giderek güçlenecek. Araştırmacılar, mevcut tekniklerle yeni fikirleri harmanlayarak LLM’leri kanıt yapısının bilinen kısımlarını keşfetmek için kullanacak ve bu da araştırma verimliliğini artıracak.
Ryu, önümüzdeki on yılda giderek daha fazla matematikçinin LLM’lerden yardım alarak kanıt iskeletlerini hazırlayacağını öngörüyor. Bu durum, deneyimli matematikçileri hüzünlendirirken, yeni neslin başarı üretmeye devam etmesini sağlayacak.